JPA N+1 문제가 발생하는 상황과 해결방법
이번 포스트에서는 JPA를 사용할 때 N+1 문제가 발생하는 상황과 3가지 해결방법을 알아보자
📌 서론
JPA에서 너무 많은 SQL 쿼리를 실행하는 것은 성능 문제의 가장 일반적인 원인 중 하나다. 잘못 구현되면, 아주 간단해 보이는 쿼리조차도 데이터베이스에 수십 또는 수백 개의 SQL 쿼리를 발생시킬 수 있다. 우리는 이런 문제를 n+1 쿼리 문제라고 한다. 이번 포스트에서는 이러한 N+1 문제에 대해서 다뤄보고자 한다.
1. N+1 문제가 발생하는 상황 설명
지금부터 N+1 문제가 발생하는 상황을 가정한다.
- 프로젝트 세팅은 다음과 같다.
| SpringBoot | 3.2 |
| Lombok | org.projectlombok:lombok |
| JPA | Spring Data JPA |
| DB | PostgreSQL |
| Querydsl | 5.0 |
| p6spy | starter 1.9.0 |
Course 엔티티는 여러 Student 엔티티와 연관이 있다.
- students 필드는 Course와 Student 사이의 일대다 관계를 나타낸다.
@Getter
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// 일대다 관계 정의: Course는 여러 Student를 가질 수 있음
@OneToMany(mappedBy = "course")
private Set<Student> students = new HashSet<>();
}Student 엔티티는 Course 엔티티와 다대일 관계에 있다.
@Getter
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// 다대일 관계 정의: Student는 하나의 Course에만 속함
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "course_id")
private Course course;
}sql 데이터를 추가한다.
-- Course 데이터 삽입
INSERT INTO course (name) VALUES ('Course1');
INSERT INTO course (name) VALUES ('Course2');
INSERT INTO course (name) VALUES ('Course3');
INSERT INTO course (name) VALUES ('Course4');
INSERT INTO course (name) VALUES ('Course5');
INSERT INTO course (name) VALUES ('Course6');
INSERT INTO course (name) VALUES ('Course7');
INSERT INTO course (name) VALUES ('Course8');
INSERT INTO course (name) VALUES ('Course9');
INSERT INTO course (name) VALUES ('Course10');
-- Student 데이터 삽입 (course_id는 삽입하는 Course의 ID에 따라 달라짐)
INSERT INTO student (name, course_id) VALUES ('Student1', 1);
INSERT INTO student (name, course_id) VALUES ('Student2', 1);
INSERT INTO student (name, course_id) VALUES ('Student3', 2);
INSERT INTO student (name, course_id) VALUES ('Student4', 2);
INSERT INTO student (name, course_id) VALUES ('Student5', 3);
INSERT INTO student (name, course_id) VALUES ('Student6', 3);
INSERT INTO student (name, course_id) VALUES ('Student7', 4);
INSERT INTO student (name, course_id) VALUES ('Student8', 4);
INSERT INTO student (name, course_id) VALUES ('Student9', 4);
INSERT INTO student (name, course_id) VALUES ('Student10', 6);컨트롤러 작성
@RequiredArgsConstructor
@RestController
@RequestMapping("/courses")
public class CourseController {
private final CourseService courseService;
@GetMapping("/print")
public void printCoursesWithStudents() {
courseService.printAllCoursesWithStudents();
}
}서비스 코드 작성
- CourseService 클래스는 CourseRepository를 통해 모든 Course 엔티티를 조회하고, 각 Course의 Student 목록을 출력하는 printAllCoursesWithStudents 메서드를 포함하고 있다.
@Slf4j
@RequiredArgsConstructor
@Service
public class CourseService {
private final CourseRepository courseRepository;
@Transactional(readOnly = true)
public void printAllCoursesWithStudents() {
List<Course> courses = courseRepository.findAll();
for (Course c : courses) {
System.out.println("Course " + c.getName() + " has students: ");
for (Student s : c.getStudents()) {
System.out.println(" - " + s.getName());
}
}
}
}리포지토리 작성
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface CourseRepository extends JpaRepository<Course, Long> {
// 추가적인 쿼리 메소드가 필요하면 여기에 정의
}
2. 컨트롤러를 호출하면 N+1 문제가 발생한다.
엔티티의 관계
- Course와 Student 간의 일대다 관계를 나타낸다. @OneToMany는 기본적으로 Lazy Loading이다.
@OneToMany(mappedBy = "course") private Set<Student> students = new HashSet<>();
IntelliJ에서 프로젝트의 root경로에 .http 파일을 생성하고 컨트롤러에 요청을 보냈다. (postman을 사용해도 된다.)
### GET 요청 예시
GET http://localhost:8080/courses/print
컨트롤러에 요청을 보냈더니 N+1 문제 발생
- CourseService의 printAllCoursesWithStudents 메서드는 먼저 courseRepository.findAll()을 통해 데이터베이스에서 모든 Course 엔티티를 조회한다. 이때, Course 엔티티는 로드되지만, 각 Course와 연관된 Student 데이터는 아직 로드되지 않는다.
- N+1 문제는 각 Course에 대해 getStudents() 메서드를 호출할 때 발생한다. JPA는 이 메서드 호출 시, 해당 Course와 연관된 Student 엔티티들을 로드하기 위해 별도의 쿼리를 실행한다. 만약 10개의 Course가 있으면, 총 11개의 쿼리가 발생한다(1개의 초기 Course 조회 쿼리 + 10개의 Student 조회 쿼리).

📌 중요한 사실
JPA는 Course와 연관된 Student가 실제로 존재하는지에 대해서는 신경 쓰지 않고 무조건 조회하는 쿼리를 실행한다. 즉, Course와 연관된 Student가 없는 경우에도 JPA는 Student의 존재 여부를 확인하기 위해 쿼리를 실행한다.
이는 데이터의 존재 여부와 무관하게 연관된 엔티티를 확인하는 JPA의 기본 동작 방식 때문이다. 그래서 나는 Course와 연관된 Student가 없는 데이터도 많이 추가했지만 10(N) 번의 쿼리가 모두 실행되었다.
실제로 SQL 로그를 확인하면, 11개의 SELECT 쿼리가 발생한 것을 볼 수 있다.

select가 몇 번 실행되었는지 검색해 봤더니 총 11 (10 + 1) 개의 select가 발생했다.
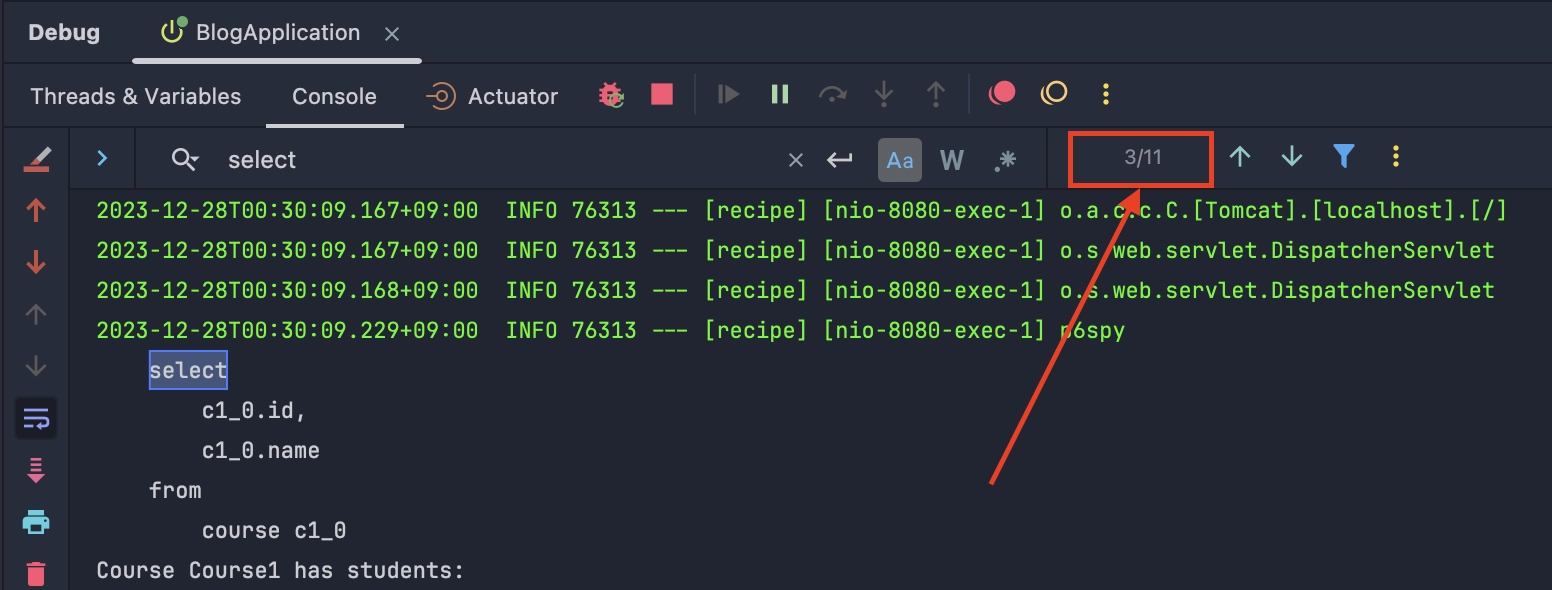
결과 쿼리를 살펴보자
- 먼저 course를 조회하는 쿼리가 1번 날아간다.
select
c1_0.id,
c1_0.name
from
course c1_0- 이후 student를 조회하는 쿼리가 10번 추가로 발생한다. where조건에 id가 1~10까지 들어가서 10번 동작한다.
select
s1_0.course_id,
s1_0.id,
s1_0.name
from
student s1_0
where
s1_0.course_id=1
📌 N+1 문제가 발생하면 안 되는 이유
N+1 문제는 데이터베이스에 많은 부담을 주고 애플리케이션의 성능을 저하시킨다. 각 Course에 대해 별도의 쿼리를 실행함으로써 발생하는 네트워크 지연, 쿼리 처리 시간 등이 누적되어 전체 시스템의 반응 시간을 늦추게 된다. 특히 Course 엔티티의 수가 많거나, 각 Course에 연결된 Student의 수가 많을 경우에는 훨씬 더 많은 쿼리가 발생하게 될 것이고 이 문제는 더욱 심각해진다.
3. N + 1 문제는 어떻게 해결해야 할까?
1. 코드 수정을 통한 해결
- 가장 기본적인 해결 방법 중 하나는 코드 자체를 수정하는 것이다. 이는 getStudents()와 같은 메서드 호출 방식을 변경하거나, 데이터를 처리하는 다른 방식을 도입하는 것을 포함한다.
2. @EntityGraph와 Fetch Join 사용
- @EntityGraph와 QueryDSL의 JOIN FETCH를 사용하는 것도 N + 1 문제를 해결하는 데 효과적이다. 이것들은 연관된 Student 엔티티를 Course 엔티티와 함께 단 한 번의 쿼리로 불러와, 별도의 쿼리 실행 없이 필요한 모든 데이터를 효율적으로 로드한다.
3. Lazy Loading과의 조합
- Lazy Loading은 기본 데이터 로딩 전략으로 유지되며, 특정 상황에서만 @EntityGraph나 Fetch Join을 사용하여 Eager Loading을 적용할 수 있다. 이 방식은 데이터 로딩을 최적화하고, 필요할 때만 모든 필요한 데이터를 한 번의 쿼리로 로드할 수 있게 해 준다. 이는 메모리 사용량과 성능에 긍정적인 영향을 미치며, 동시에 N + 1 문제를 효과적으로 해결한다.
📌 결론
N + 1 문제의 해결은 데이터 로딩 전략의 균형을 맞추는 것이 핵심이다. 기본적으로는 Lazy Loading을 사용하여 불필요한 데이터 로드를 방지하고, 필요한 경우에만 @EntityGraph나 Fetch Join을 활용해 Eager Loading으로 전환하여 효율적인 데이터 로드를 달성한다.
4. EntityGraph를 사용하여 N+1문제 해결하기
📌 @EntityGraph의 동작 이해
@EntityGraph는 JPA에서 제공하는 기능으로, 엔티티를 조회할 때 특정 연관 관계를 Eager Loading 방식으로 함께 로드하는 데 사용된다. 이 방법을 사용하면, 연관된 엔티티들을 별도의 쿼리 없이 한 번의 쿼리로 함께 로드할 수 있다.
Course 엔티티에 @NamedEntityGraph 적용
- 먼저 Course 엔티티에 @NamedEntityGraph 어노테이션을 적용하여 students 컬렉션을 Eager Loading 방식으로 로드하도록 설정한다. 이렇게 설정함으로써, Course 조회 시 연관된 Student 엔티티들도 함께 로드되도록 한다.
@Getter
@Entity
@NamedEntityGraph(name = "Course.students", attributeNodes = @NamedAttributeNode("students"))
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// 일대다 관계 정의: Course는 여러 Student를 가질 수 있음
@OneToMany(mappedBy = "course")
private Set<Student> students = new HashSet<>();
}
CourseRepository에 @EntityGraph 적용
- CourseRepository 인터페이스에서 @EntityGraph 어노테이션을 사용하여 findAllWithStudents 메서드 정의한다. 이 메서드는 Course 엔티티를 조회할 때 students 컬렉션을 Eager Loading 방식으로 함께 가져오도록 한다. 이는 추가적인 쿼리 없이 필요한 모든 데이터를 효율적으로 로드하는 방법이다.
@Repository
public interface CourseRepository extends JpaRepository<Course, Long> {
@EntityGraph(attributePaths = {"students"})
@Query("SELECT c FROM Course c")
List<Course> findAllWithStudents();
}CourseService에서 @EntityGraph 적용 메서드 사용
- 마지막으로, CourseService 클래스에서 findAllWithStudents 메서드를 사용하여 모든 Course와 연관된 Student들을 한 번의 쿼리로 가져온다. 이는 N+1 문제를 해결하고 애플리케이션의 전반적인 성능을 개선하는 데 기여한다.
@Slf4j
@RequiredArgsConstructor
@Service
public class CourseService {
private final CourseRepository courseRepository;
@Transactional(readOnly = true)
public void printAllCoursesWithStudents() {
// List<Course> courses = courseRepository.findAll(); // N + 1이 발생하는 로직
List<Course> courses = courseRepository.findAllWithStudents(); // 엔티티 그래프 전용
for (Course c : courses) {
System.out.println("Course " + c.getName() + " has students: ");
for (Student s : c.getStudents()) {
System.out.println(" - " + s.getName());
}
}
}
}수정 후 실행결과
- 이렇게 수정하면, Course 엔티티를 조회할 때 각 Course에 연관된 모든 Student들을 한 번의 쿼리로 가져오므로, N+1 문제를 해결할 수 있다. 결과적으로, 데이터베이스에 대한 쿼리 수를 크게 줄이고 애플리케이션의 성능을 개선할 수 있다.
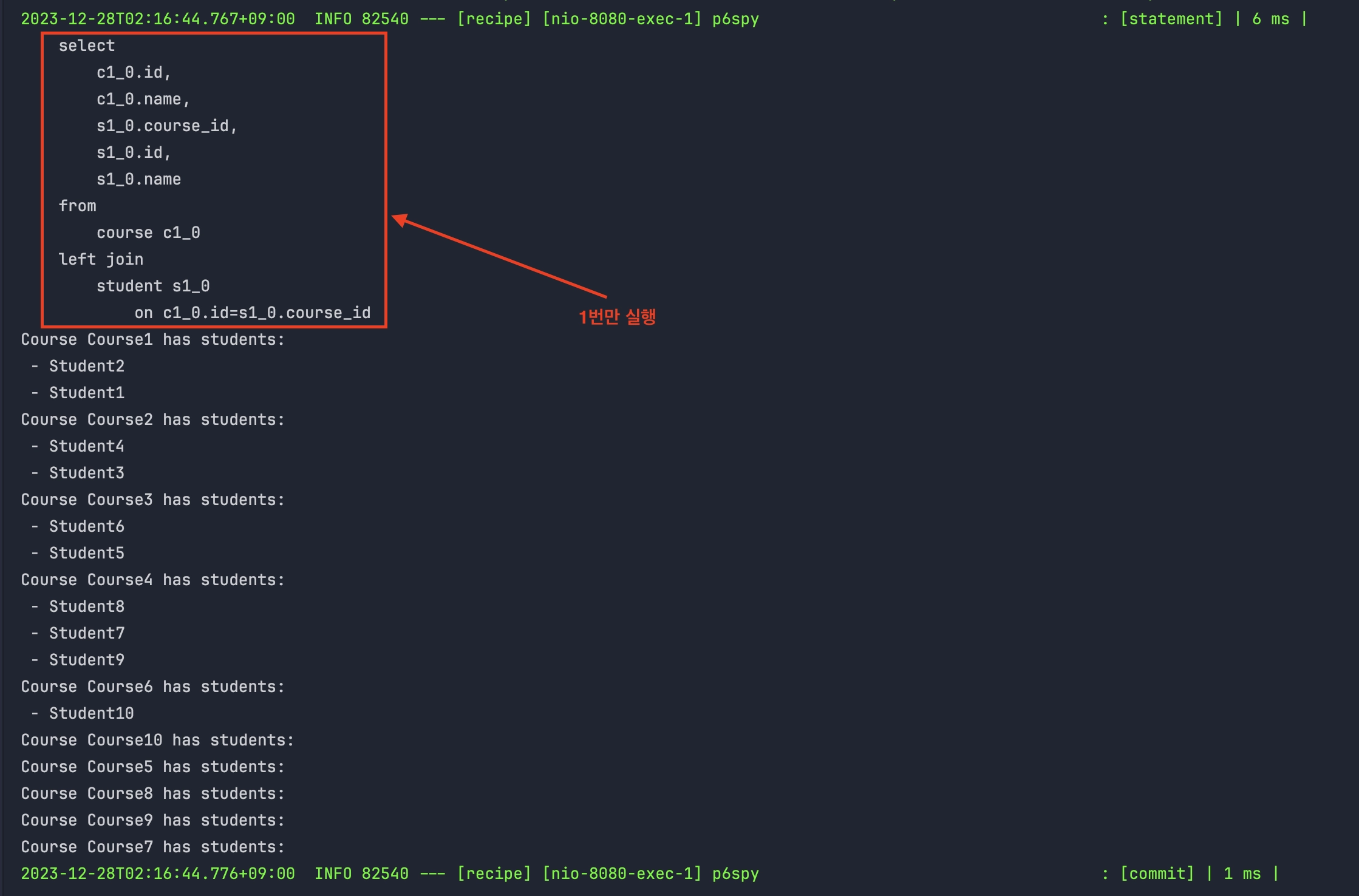
쿼리를 살펴보자
- N+1이 발생했을때와 달리 1번의 쿼리로 모든것이 해결되었다.
select
c1_0.id,
c1_0.name,
s1_0.course_id,
s1_0.id,
s1_0.name
from
course c1_0
left join
student s1_0
on c1_0.id=s1_0.course_id
5. @EntityGraph 적용 전과 후의 쿼리 비교분석
N+1 문제가 발생하는 쿼리
첫 번째 쿼리
- 모든 Course 엔티티를 조회한다. 이 쿼리는 Course 테이블에 대한 단일 조회 쿼리로, Course 엔티티의 기본 정보만을 로드한다.
select
c1_0.id,
c1_0.name
from
course c1_0
각 Course마다 추가 쿼리
- 각 Course 엔티티에 연관된 Student 엔티티들을 가져오기 위해 추가적인 쿼리가 실행된다. 만약 10개의 Course가 있다면, 각각에 대해 별도의 쿼리가 실행되어 총 10개의 추가 쿼리가 발생한다. 이는 N+1 문제의 전형적인 사례로, 비효율적인 데이터 로드를 초래한다.
select
s1_0.course_id,
s1_0.id,
s1_0.name
from
student s1_0
where
s1_0.course_id = 1
@EntityGraph 적용 후 쿼리
단일 조인 쿼리
- @EntityGraph를 적용하면, Course와 연관된 Student 엔티티들을 한 번의 쿼리로 함께 로드한다. 이 쿼리는 Course 엔티티를 조회하면서 동시에 각 Course에 연관된 모든 Student들을 LEFT JOIN을 통해 함께 가져온다. 결과적으로, 이는 하나의 쿼리로 모든 필요한 데이터를 효율적으로 로드하는 방식이며, N+1 문제를 해결한다.
select
c1_0.id,
c1_0.name,
s1_0.course_id,
s1_0.id,
s1_0.name
from
course c1_0
left join
student s1_0
on c1_0.id=s1_0.course_id
📌 결론
@EntityGraph의 사용은 각 Course 엔티티에 대해 별도의 쿼리를 실행하지 않고, 한 번의 조인 쿼리로 모든 관련 데이터를 효율적으로 로드하는 데 중점을 둔다. 이로 인해, 애플리케이션의 성능이 개선되며, 데이터베이스에 대한 부담이 감소한다. N+1 문제를 해결함으로써 데이터 액세스의 효율성이 크게 향상되는 것이 이 방식의 주요 이점이다.
6. Join Fetch를 사용하여 N+1문제 해결하기
📌 잠깐! JOIN FETCH란?
JOIN FETCH는 JPA에서 연관 엔티티를 한 번의 쿼리로 함께 로드하는 방식으로, N+1 문제를 해결하는 데 중요한 역할을 한다. N+1 문제는 하나의 엔티티를 조회할 때 그와 연관된 여러 엔티티들을 개별 쿼리로 로드해야 할 때 발생하는데, JOIN FETCH를 사용하면 이 문제를 효율적으로 해결할 수 있다. JOIN FETCH는 연관 엔티티를 즉시 로드하여 연관된 엔티티들을 한 번의 쿼리로 함께 가져와서, 각각의 엔티티에 대한 별도의 쿼리 실행 없이 필요한 모든 데이터를 로드할 수 있다.
querydsl 커스텀 인터페이스 선언
- QueryDSL 구현을 위한 첫 단계는 CourseRepositoryCustom라는 커스텀 인터페이스를 선언하는 것이다. 이 인터페이스는 JOIN FETCH를 사용하는 쿼리를 실행하는 메서드를 포함한다.
public interface CourseRepositoryCustom {
List<Course> findAllWithStudentsFetchJoin();
}커스텀 인터페이스 구현
- 다음으로, CourseRepositoryCustom 인터페이스의 구현체인 CourseRepositoryCustomImpl 클래스를 작성한다. 여기서는 QueryDSL의 JPAQueryFactory를 사용하여, Course 엔티티와 연관된 Student 엔티티들을 한 번의 쿼리로 함께 로드하는 로직을 구현한다.
@Repository
public class CourseRepositoryCustomImpl implements CourseRepositoryCustom {
private final JPAQueryFactory queryFactory;
public CourseRepositoryCustomImpl(EntityManager entityManager) {
this.queryFactory = new JPAQueryFactory(entityManager);
}
@Override
public List<Course> findAllWithStudentsFetchJoin() {
QCourse course = QCourse.course;
return queryFactory
.selectFrom(course)
.leftJoin(course.students).fetchJoin()
.fetch();
}
}JpaRepository 확장하기
- 기본 JPA 리포지토리 인터페이스인 CourseRepository에는 findAllWithStudents 메서드와 함께, CourseRepositoryCustom 인터페이스도 확장하여 추가한다. 이렇게 함으로써, CourseRepository를 통해 커스텀 쿼리 메서드에 접근할 수 있다.
@Repository
public interface CourseRepository extends JpaRepository<Course, Long> , CourseRepositoryCustom{
@EntityGraph(attributePaths = {"students"})
@Query("SELECT c FROM Course c")
List<Course> findAllWithStudents();
}서비스 로직 수정
- 마지막으로, CourseService 클래스에서 findAllWithStudentsFetchJoin 메서드를 사용하여 Course와 연관된 Student들을 한 번의 쿼리로 가져오도록 수정한다.
@Slf4j
@RequiredArgsConstructor
@Service
public class CourseService {
private final CourseRepository courseRepository;
@Transactional(readOnly = true)
public void printAllCoursesWithStudents() {
// List<Course> courses = courseRepository.findAll(); // N + 1이 발생하는 로직
// List<Course> courses = courseRepository.findAllWithStudents(); // 엔티티 그래프 로직
List<Course> courses = courseRepository.findAllWithStudentsFetchJoin(); // Join Fetch 로직
for (Course c : courses) {
System.out.println("Course " + c.getName() + " has students: ");
for (Student s : c.getStudents()) {
System.out.println(" - " + s.getName());
}
}
}
}실행 결과
- QueryDSL을 사용하여 구현된 JOIN FETCH 쿼리는 @EntityGraph를 사용했을 때와 동일한 결과를 가져온다. 이 접근 방식은 Course 엔티티와 연관된 Student 엔티티들을 한 번의 쿼리로 함께 조회한다.
- Course 테이블과 Student 테이블 간의 LEFT JOIN을 수행하여, 각 Course와 연관된 Student들을 로드하는 것이다.
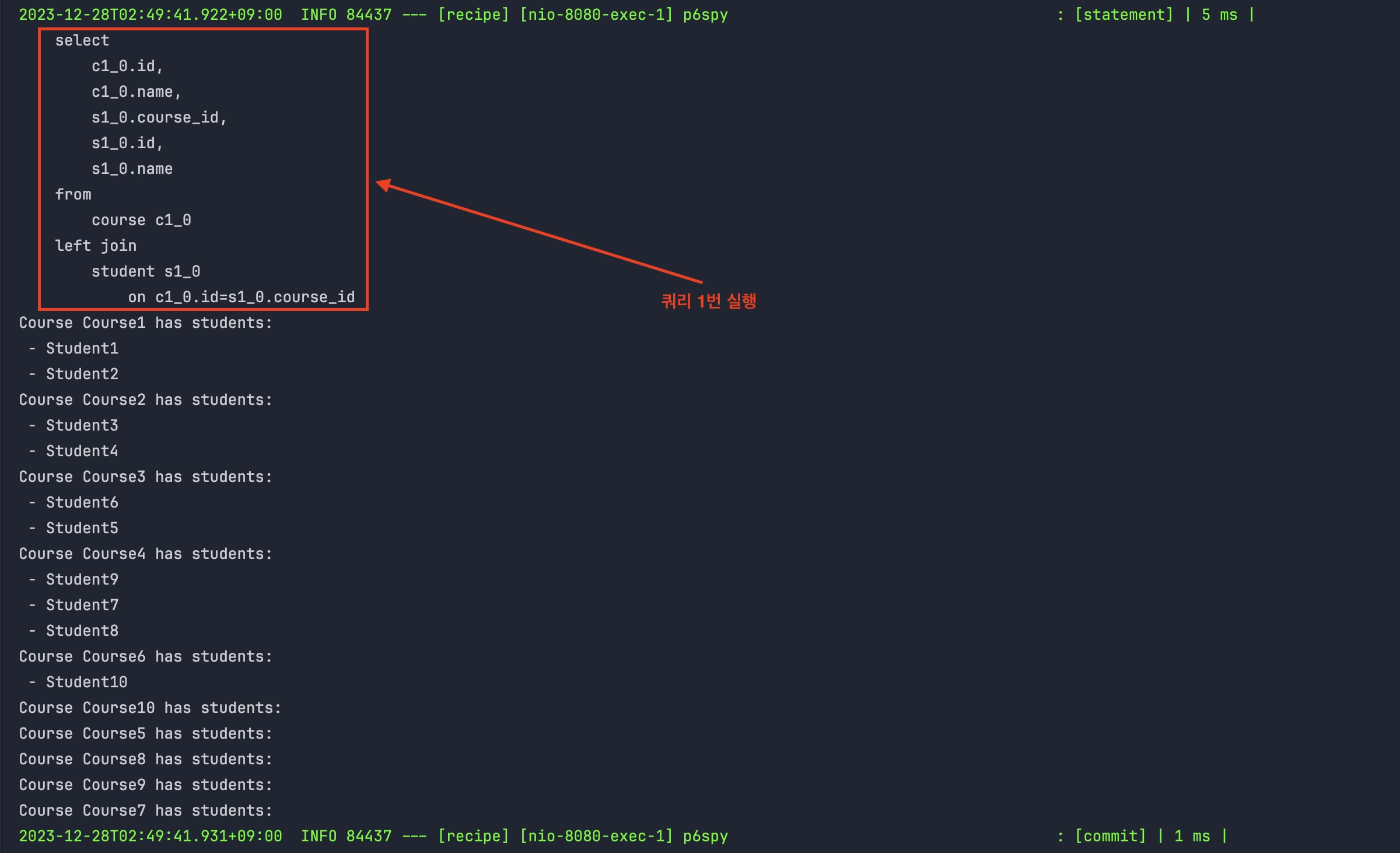
QueryDSL을 사용한 JOIN FETCH 쿼리 분석
- 이 쿼리는 Course 엔티티를 조회할 때 JOIN FETCH를 사용하여 Student 컬렉션을 즉시 로드하는 데 사용되며, N+1 문제를 해결하고 애플리케이션의 성능을 개선하는 데 중요한 역할을 한다.
- 이 방식은 데이터 로딩을 최적화하고, 관련 엔티티를 한 번의 쿼리로 효율적으로 로드할 수 있으며, 애플리케이션의 성능 향상에 기여한다.
select
c1_0.id,
c1_0.name,
s1_0.course_id,
s1_0.id,
s1_0.name
from
course c1_0
left join
student s1_0
on c1_0.id=s1_0.course_id
📌 결론
JOIN FETCH를 사용하는 것은 데이터 로드의 효율성을 크게 향상시키며, N+1 문제를 해결하는데 매우 효과적이다. QueryDSL을 사용하면 이러한 쿼리를 더 타입 안전하고 가독성 있게 구현할 수 있어서 복잡한 데이터 로드 요구 사항을 쉽게 처리할 수 있다.
7. Batch Size를 사용하여 N+1 문제 해결하기
📌 Batch Size란?
Batch Size는 JPA에서 제공하는 기능으로, 연관된 엔티티를 일정한 크기의 묶음(batch)으로 로드하는 방법이다. 이를 통해, 많은 수의 연관 엔티티를 한 번에 조회할 때 발생하는 N+1 문제를 효과적으로 줄일 수 있다.
Batch Size의 동작 원리
- Batch Size를 사용하면, JPA는 설정된 크기만큼의 연관 엔티티를 단일 쿼리로 로드할 수 있다. 예를 들어, Batch Size를 10으로 설정하고 30개의 연관 엔티티를 로드해야 하는 경우, JPA는 총 3번의 쿼리를 실행하게 된다.
(30개를 10개씩 나누어서). 이는 기존의 N+1 문제에서 발생하는 수많은 쿼리 수를 크게 줄여 성능을 개선하는 데 도움이 된다.
Batch Size 설정 방법
- JPA에서 Batch Size를 설정하는 두 가지 주요 방법이 있다. 하나는 @BatchSize 어노테이션을 사용하는 것이고, 다른 하나는 application.properties 또는 application.yml 파일에서 전역 설정으로 batch size를 지정하는 것이다.
Batch Size의 장점과 주의점
- Batch Size의 주요 장점은 N+1 문제를 줄이면서도 쿼리의 수를 관리할 수 있다는 것이다. 하지만 Batch Size를 너무 크게 설정하면, 한 번에 로드되는 데이터 양이 많아져서 메모리 사용량이 증가할 수 있다.
반면에 너무 작게 설정하면 여전히 많은 수의 쿼리가 발생할 수 있다. 따라서 애플리케이션의 특성과 데이터베이스의 부하를 고려해 적절한 Batch Size 값을 설정하는 것이 중요하다.
Batch Size 적용 예시 1: @BatchSize 어노테이션 사용
- 예를 들어, Student 엔티티에 Batch Size를 적용하려면 다음과 같이 설정할 수 있다. 아래의 코드에서 @BatchSize(size = 10)은 JPA에게 Course 엔티티를 로드할 때 연관된 Student 엔티티를 10개 단위로 쿼리해오라고 지시한다.
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "course", fetch = FetchType.LAZY)
@BatchSize(size = 10)
private Set<Student> students = new HashSet<>();
}
Batch Size 적용 예시 2:application.properties 또는 application.yml에서 전역 설정
- 전역 설정을 사용하면, 애플리케이션 내 모든 엔티티와 컬렉션에 대해 Batch Size를 일괄적으로 설정할 수 있다. 이 설정은 애플리케이션 내 모든 Lazy 로딩을 사용하는 컬렉션에 대해 적용된다.
jpa:
properties:
hibernate:
default_batch_fetch_size: 10
📌 어떤 방법을 사용하는 게 좋을까?
두 방법 중 하나를 선택할 때는 사용 사례를 고려해야 한다. 어노테이션을 사용하면 더 세밀한 제어가 가능하지만, 모든 엔티티와 컬렉션에 동일한 Batch Size를 적용하고 싶다면 전역 설정이 더 편리할 것이다. 전역 설정을 사용하면 모든 Lazy 로딩 컬렉션에 대한 성능 최적화를 일괄적으로 적용할 수 있어서, 일관된 성능 향상을 기대할 수 있다.
컨트롤러 호출 결과
- 총 2번의 쿼리가 발생했다. 첫 번째 쿼리는 모든 Course 엔티티를 로드하고, 두 번째 쿼리는 설정된 Batch Size에 따라 여러 Course에 연관된 Student들을 한 번에 로드한다.
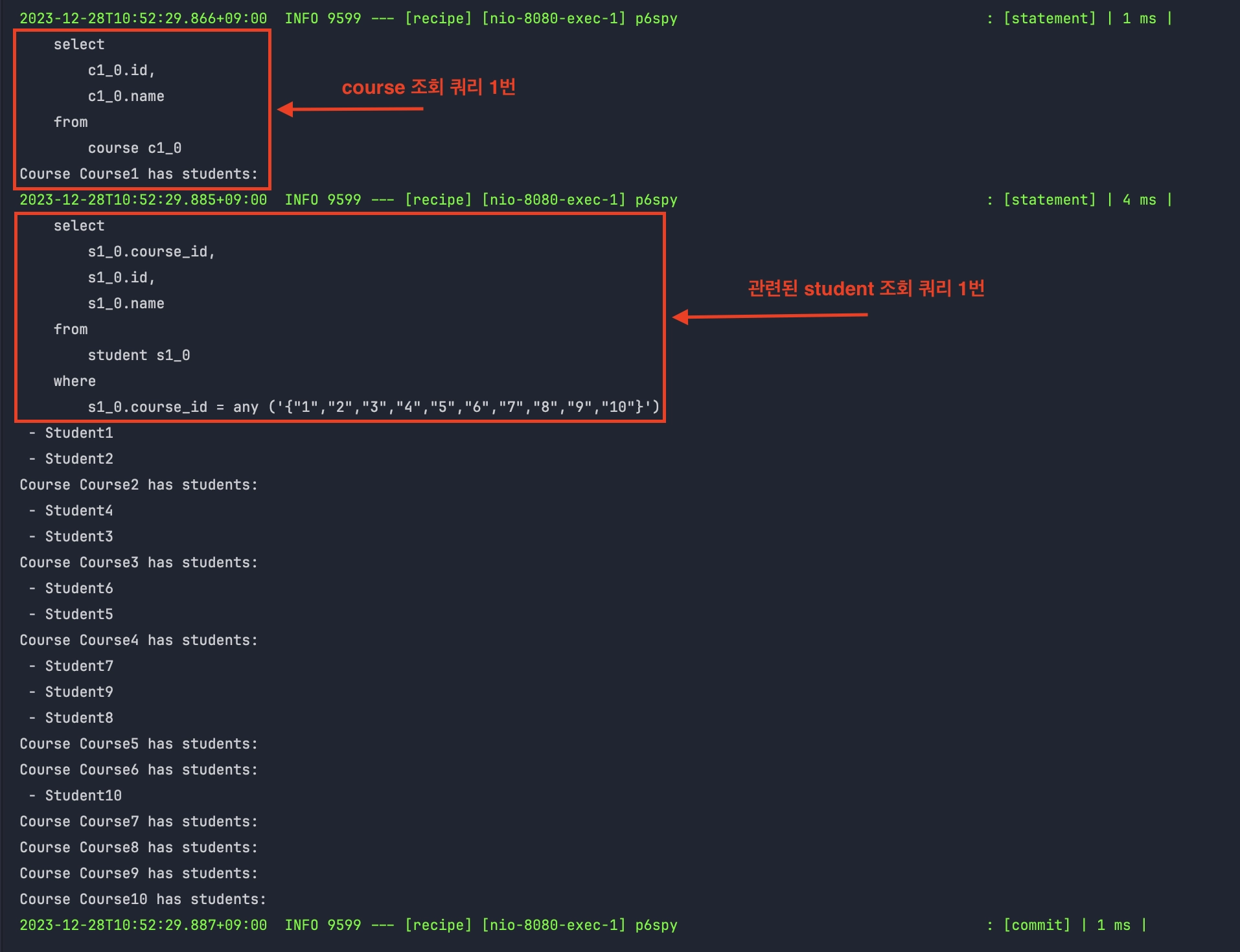
쿼리 분석하기
- 첫 번째 쿼리가 실행되어 course에 대해서 조회한다.
select
c1_0.id,
c1_0.name
from
course c1_0- 두 번째 쿼리가 실행되어 in절로 연관된 모든 student를 조회한다.
select
s1_0.course_id,
s1_0.id,
s1_0.name
from
student s1_0
where
s1_0.course_id = any ('{"1","2","3","4","5","6","7","8","9","10"}')
8. N+1 문제 해결을 위해 Batch Size와 @EntityGraph, Fetch join를 사용할 때의 차이점
Batch Size 설정
- Batch Size를 사용할 때, JPA는 연관된 엔티티를 미리 정의된 크기의 배치로 로드한다. 이 경우, 연관된 엔티티들을 불러오기 위해 'IN' 절을 사용하는 단일 쿼리가 실행된다.
- 이 쿼리는 설정된 Batch Size에 따라 여러 ID를 한 번에 조회한다. 이 방법은 여러 Course 엔티티에 대한 Student 엔티티들을 불러올 때 N+1 문제를 줄여주지만, 위의 결과를 보면 알 수 있듯이 여전히 두 번의 쿼리가 필요하다(하나는 Course를 로드하고, 다른 하나는 관련 Student들을 로드한다).
select
s1_0.course_id,
s1_0.id,
s1_0.name
from
student s1_0
where
s1_0.course_id = any ('{"1","2","3","4","5","6","7","8","9","10"}')Fetch Join 또는 @EntityGraph 사용
- Fetch Join 또는 @EntityGraph를 사용하면, 관련 엔티티들을 하나의 쿼리에서 함께 로드한다. 이 방법은 JOIN을 사용하여 Course와 Student를 함께 조회한다.
- 이 접근 방식은 하나의 쿼리로 모든 관련 데이터를 가져와서 N+1 문제를 완전히 해결한다. 하지만 큰 데이터셋을 다룰 때 메모리 사용량이 증가할 수 있다.
select
c1_0.id,
c1_0.name,
s1_0.course_id,
s1_0.id,
s1_0.name
from
course c1_0
left join
student s1_0
on c1_0.id=s1_0.course_id
📌 결론
Batch Size는 여전히 복수의 쿼리를 사용하지만, 쿼리의 수를 제한하여 N+1 문제를 완화시킨다. 반면, Fetch Join 또는 @EntityGraph는 한 번의 쿼리로 모든 데이터를 가져와서 N+1 문제를 완전히 해결하지만, 메모리 사용량이 증가할 수 있는 단점이 있다.
9. 최종정리
N+1 문제 상황
- N+1 문제는 JPA와 같은 ORM을 사용할 때 자주 발생하는 문제다. 이는 데이터베이스에서 연관된 엔티티를 조회할 때 발생하는 비효율적인 쿼리 패턴을 나타낸다. 예를 들어, Course 엔티티를 조회하는 초기 쿼리가 있고, 이후 각 Course 엔티티에 대해 연관된 Student 엔티티들을 가져오기 위한 추가적인 쿼리가 실행된다.
- 만약 10개의 Course가 있다면, 총 11개의 쿼리가 실행된다(1개의 초기 쿼리 + 각 Course에 대한 10개의 추가 쿼리). 이러한 상황은 데이터베이스에 큰 부담을 주며, 애플리케이션의 성능 저하를 일으키게 된다.
@EntityGraph 사용
- @EntityGraph는 JPA에서 제공하는 해결책 중 하나다. 이 어노테이션을 사용하면, 연관된 엔티티를 Eager 로딩 방식으로 함께 조회할 수 있다. 이는 단일 쿼리를 통해 Course 엔티티와 연관된 Student 엔티티들을 함께 로드하는 방식으로, N+1 문제를 해결한다.
- @EntityGraph를 사용하면, 관련 데이터를 한 번의 쿼리로 효율적으로 로드하여 데이터베이스에 대한 요청 수를 줄이고, 전반적인 애플리케이션의 성능을 개선할 수 있다.
QueryDSL의 JOIN FETCH 사용
- QueryDSL을 사용한 JOIN FETCH 구현은 N+1문제를 해결하는 또 다른 방법이다. QueryDSL을 사용하면, Course 엔티티와 연관된 Student 엔티티들을 LEFT JOIN과 fetchJoin() 메서드를 통해 한 번의 쿼리로 함께 로드할 수 있다.
- 이 접근 방식은 N+1 문제를 해결하는 동시에, QueryDSL의 타입 안전성과 유연성을 활용할 수 있는 장점이 있다. QueryDSL은 복잡한 쿼리를 쉽고 가독성 있게 작성할 수 있도록 도와주며, 이를 통해 쿼리의 유지보수성과 확장성이 크게 향상된다.
Batch Size 사용
- Batch Size 설정은 JPA의 또 다른 해결책으로, 연관된 엔티티를 일정한 크기의 묶음(batch)으로 로드하는 방식이다. Batch Size를 설정함으로써, N+1 문제를 완화할 수 있다.
- 이 방법은 데이터를 작은 배치로 나누어 쿼리를 수행하므로, 여러 쿼리가 실행되더라도 그 수를 제한할 수 있다. 이 방식은 특히 대량의 연관 데이터를 처리해야 할 때 유용하며, 성능 향상과 메모리 사용의 균형을 맞추는 데 도움이 된다.
📌 결론
N+1 문제는 ORM 사용 시 흔히 발생하는 성능 문제이며, @EntityGraph, QueryDSL의 JOIN FETCH, 그리고 Batch Size 설정은 이 문제를 해결하는 세 가지 주요 방법이다.
@EntityGraph와 JOIN FETCH는 간편한 선언적 접근 방식과 복잡한 쿼리의 구성을 통해 N+1 문제를 해결하는 반면, Batch Size 설정은 쿼리 수를 제한하여 이 문제를 완화한다. 이 세 가지 방법 모두 N+1 문제를 효과적으로 해결하고, 애플리케이션의 성능을 개선하는 데 크게 기여한다.
참조
How to Improve JPA Performance | JRebel by Perforce
Subpar JPA performance might have a variety of causes. In this blog, we describe how to use three JPA features to help avoid issues.
www.jrebel.com
사용한 코드는 아래의 git에 있습니다.
GitHub - wlsdks/blog_Coding
Contribute to wlsdks/blog_Coding development by creating an account on GitHub.
github.com