시작하며
안녕하세요, 개발자 stark입니다!
오랜만에 글을 적게 되었는데요. 오늘은 제가 실무에서 가장 많이 고민했던 주제 중 하나인 DDD(Domain-Driven Design)의 애그리게잇 설계에 대해 다뤄보려고 합니다. 특히 Spring과 Java 환경에서 이를 어떻게 효과적으로 구현할 수 있는지, 실제 경험을 바탕으로 공유해 드리겠습니다.
애그리게잇은 DDD에서 가장 핵심적인 개념임에도 불구하고 이를 적절히 설계하는 데 어려움을 겪습니다. 저 같은 경우에는 매번 로직을 작성하면서 "이 엔티티는 어느 애그리게잇에 속해야 할까?", "애그리게잇 경계를 어디까지 설정해야 할까?" 등의 고민이 끊이지 않았습니다. 그래서 오늘은 최대한 실용적인 관점에서 접근해 보겠습니다.
도메인 주도 설계와 애그리게잇의 중요성
도메인 주도 설계(DDD)는 복잡한 비즈니스 도메인을 효과적으로 모델링하기 위한 접근 방식입니다. 에릭 에반스(Eric Evans)가 2003년에 소개한 이 개념은 소프트웨어 개발에서 기술적 복잡성보다 도메인의 복잡성에 집중하는 것이 중요하다는 철학을 담고 있습니다.
그중에서도 '애그리게잇(Aggregate)'은 관련된 객체 집합을 하나의 단위로 취급하여 도메인 모델의 일관성을 보장하는 개념입니다. 제가 처음 DDD를 하게 되었을 때 가장 먼저 Aggreagate을 이해하고자 했지만 정말 쉽지 않았습니다. 한참 어려움을 겪던 중에 제게 가장 힘이 되어준 것은 NHN, 배민의 세미나였습니다.
같은 주제의 세미나를 10번은 본 것 같습니다. 6번쯤 봤을 때 문득 이런 생각이 들었던 것 같습니다. 애그리게잇(집합)은 하나의 큰 단위(묶음)로서 모든 작업을 이 묶음(변경, 조회, 수정, 삭제) 안에서 이루어진다는 것입니다. 그리고 이 묶음의 대장이 되는 녀석을 Aggregate Root라고 부른다고 생각하게 되었습니다.
그러니 처음부터 가능한 이 묶음을 잘 구성하는 것이 가장 중요하다는 것입니다.
도메인 컨텍스트 이해하기: 전자상거래(이커머스)
애그리게잇 설계를 이해하기 위해서는 가장 먼저 도메인 컨텍스트를 명확히 파악해야 합니다. 저는 우리가 이해하기 쉬울만한 전자상거래(이커머스) 도메인을 예로 들어보겠습니다.
전자상거래 시스템은 크게 다음과 같은 서브 도메인으로 구분할 수 있습니다. (컨텍스트 맵)

1. 핵심 도메인 (Core Domain)
기업의 주요 경쟁력을 결정하는 가장 중요한 비즈니스 영역이며, 반드시 사내에서 직접 개발합니다.
- 주문 관리 (Order Management): 고객의 주문 처리 및 상태 관리
- 상품 관리 (Product Management): 상품 등록, 재고 관리, 가격 정책
- 프로모션 (Promotion): 할인, 쿠폰, 특별 이벤트 관리
2. 지원 서브 도메인 (Supporting Subdomain)
핵심 도메인을 돕기 위해 존재하며, 외부 시스템과 연동하거나 자체적으로 일부 개발하여 사용하는 영역입니다. 비즈니스 로직을 일부 포함합니다.
- 결제 시스템 (Payment): 다양한 결제 수단 연동 및 처리
- 배송 관리 (Shipping): 물류 센터 연동, 배송 추적
- 고객 서비스 (Customer Service): 문의, 불만 처리, 반품/교환
3. 일반 서브 도메인 (Generic Subdomain)
비즈니스 경쟁력과 직접적인 관련이 없으며, 보편적인 기능으로서 주로 외부의 범용 솔루션을 가져다 쓰는 영역입니다. 사내에서 개발하더라도 큰 차별화를 가져다주지 않는 경우가 많습니다.
- 회원 관리 (Membership): 회원 가입, 인증, 프로필 관리
- 알림 서비스 (Notification): 이메일, SMS, 푸시 알림
- 데이터 분석 (Analytics): 판매 통계, 사용자 행동 분석
애그리게잇 설계의 핵심 원칙
애그리게잇을 설계할 때 염두해야 하는 원칙들은 다음과 같습니다.
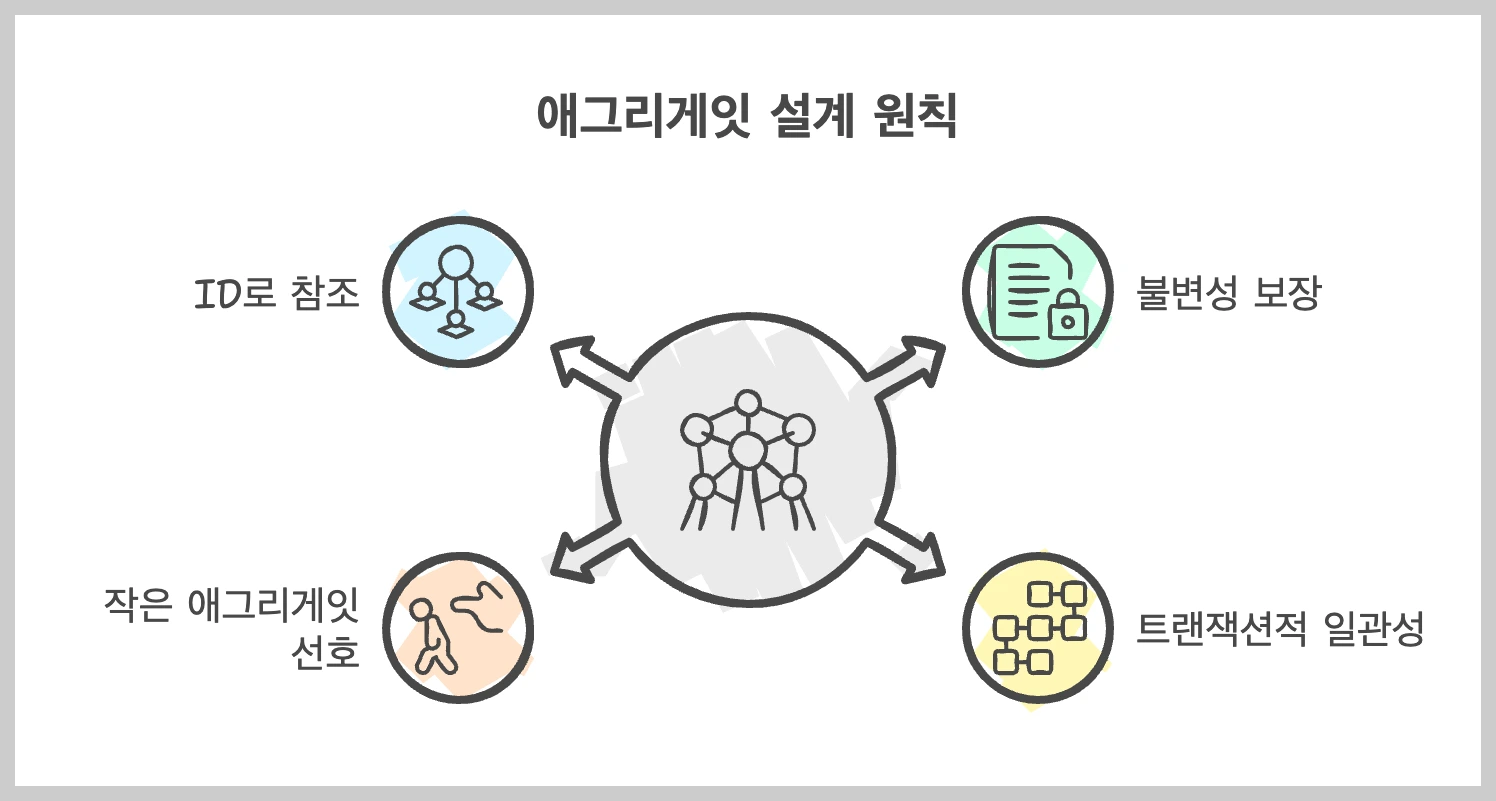
1. 불변성 보장 원칙
애그리게잇은 비즈니스 규칙에 따라 일관성 있는 상태를 유지해야 합니다. 내부 객체들은 항상 유효한 상태를 가져야 하며, 이를 위해 애그리게잇 루트를 통해서만 내부 객체에 접근할 수 있어야 합니다.
2. 트랜잭션적 일관성
한 트랜잭션 내에서는 하나의 애그리게잇만 수정하는 것이 이상적입니다. 여러 애그리게잇을 한 트랜잭션에서 수정하면 결합도가 높아지고 확장성이 저하됩니다.
3. 작은 애그리게잇 선호
큰 애그리게잇보다는 작은 애그리게잇을 여러 개 사용하는 것이 좋습니다. 큰 애그리게잇은 성능 문제와 동시성 충돌을 유발할 수 있습니다.
4. ID로 참조
다른 애그리게잇은 직접 참조하지 않고 ID로만 참조합니다. 이렇게 하면 애그리게잇 간의 결합도를 낮출 수 있습니다.
실전 애그리게잇 설계: 주문 도메인
이제 실제로 주문 도메인의 애그리게잇을 설계 해봅시다. 주문 도메인을 분석해 보면 다음과 같은 개념들이 있습니다.
- 주문 (Order)
- 주문 항목 (Order Item)
- 결제 정보 (Payment)
- 배송 정보 (Shipping)
- 할인 적용 내역 (Discount)
- 고객 정보 (Customer)

이 모든 개념을 하나의 애그리게잇으로 묶어야 할까요? 아니면 분리해야 할까요? 이 질문에 답하기 위해 각 개념 간의 관계와 불변 조건을 분석해 보겠습니다.
애그리게잇 경계 설정
주문 도메인에서 가장 중요한 불변 조건은 다음과 같습니다.
- 주문은 항상 하나 이상의 주문 항목을 가져야 함
- 각 주문 항목의 가격과 수량은 주문 생성 후에는 변경될 수 없음
- 주문 총액은 모든 주문 항목의 가격 합계와 할인, 세금, 배송료 등을 고려하여 계산됨
- 주문 상태는 정해진 흐름에 따라 변경되어야 함 (예: 결제 대기 → 결제 완료 → 배송 준비 → 배송 중 → 배송 완료)
이런 불변 조건을 고려할 때, 주문(Order)과 주문 항목(Order Item)은 강한 일관성이 요구되므로 같은 애그리게잇에 포함되어야 합니다. 그러나 고객 정보(Customer)는 여러 주문에서 공유될 수 있으므로 별도의 애그리게잇으로 분리하고 ID로 참조하는 것이 좋습니다. 결제 정보(Payment)와 배송 정보(Shipping) 또한 별도의 애그리게잇으로 분리하고 ID를 참조했습니다.
주문 애그리게잇 상세 설계
- 최종적으로 주문 애그리게잇은 다음과 같이 구성될 것입니다.
- 이 구조에서 Order가 애그리게잇 루트로, 모든 내부 엔티티와 값 객체에 대한 접근과 변경을 제어합니다.
Order (애그리게잇 루트)
├── OrderId
├── OrderStatus
├── OrderItems
├── CustomerId (다른 애그리게잇 참조)
├── PaymentId (다른 애그리게잇 참조)
└── ShipmentId (다른 애그리게잇 참조)
Payment (애그리게잇 루트)
├── PaymentId
├── OrderId (다른 애그리게잇 참조)
└── PaymentDetails
Shipment (애그리게잇 루트)
├── ShipmentId
├── OrderId (다른 애그리게잇 참조)
└── ShippingDetails- 주문 Aggregate을 그림으로 표현하면 다음과 같습니다.

Java와 Spring으로 애그리게잇 구현하기
이제 앞서 설계한 주문 애그리게잇을 Java와 Spring 환경에서 어떻게 구현할 수 있는지 살펴봅시다.
애그리게잇 루트 구현
- 먼저 주문 애그리게잇 루트인 Order 클래스를 구현해 보겠습니다.
// 주문 애그리게잇
@Entity
public class Order {
@EmbeddedId
private OrderId id;
@Enumerated(EnumType.STRING)
private OrderStatus status;
@Embedded
private CustomerId customerId;
@ElementCollection
private List<OrderItem> orderItems = new ArrayList<>();
// 다른 애그리게잇 ID 참조
@Embedded
private PaymentId paymentId; // 결제 ID 참조
@Embedded
private ShipmentId shipmentId; // 배송 ID 참조
// ShippingAddress는 Value Object로 남겨둠
// (배송 주소는 주문 시점에 결정되는 정보이기 때문)
@Embedded
private ShippingAddress shippingAddress;
// ...나머지 메서드들
}
// 결제 애그리게잇
@Entity
public class Payment {
@EmbeddedId
private PaymentId id;
@Embedded
private OrderId orderId; // 주문 ID 참조
@Enumerated(EnumType.STRING)
private PaymentStatus status;
@Embedded
private Money amount;
@Enumerated(EnumType.STRING)
private PaymentMethod method;
@Embedded
private PaymentDate paymentDate;
// ...결제 관련 메서드들
}
// 배송 애그리게잇
@Entity
public class Shipment {
@EmbeddedId
private ShipmentId id;
@Embedded
private OrderId orderId; // 주문 ID 참조
@Enumerated(EnumType.STRING)
private ShipmentStatus status;
@Embedded
private TrackingNumber trackingNumber;
@Embedded
private ShipmentDate shipmentDate;
// ...배송 관련 메서드들
}이 구현에서 주목할 점은 다음과 같습니다.
- 캡슐화: 모든 변경은 도메인 로직을 통해서만 이루어지며, 내부 상태는 직접 변경할 수 없습니다.
- 불변 조건 강제: 상태 변경 메서드는 항상 검증 로직을 통해 비즈니스 규칙을 지키도록 합니다.
- 풍부한 도메인 모델: 애그리게잇 루트가 단순히 데이터를 담는 컨테이너가 아니라, 중요한 비즈니스 로직을 캡슐화합니다.
- 정적 팩토리 메서드: 생성자 대신 의미 있는 이름의 팩토리 메서드를 제공합니다.
값 객체(Value Object) 구현
- 다음은 주문 ID와 같은 값 객체의 구현 예시입니다.
@Getter
@Embeddable
public class OrderId implements Serializable {
@Column(name = "order_id")
private String value;
// JPA 요구사항
protected OrderId() {}
private OrderId(String value) {
this.value = value;
}
public static OrderId of(String value) {
if (value == null || value.isBlank()) {
throw new IllegalArgumentException("OrderId cannot be null or empty");
}
return new OrderId(value);
}
public static OrderId generate() {
return new OrderId(UUID.randomUUID().toString());
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
OrderId orderId = (OrderId) o;
return value.equals(orderId.value);
}
@Override
public int hashCode() {
return Objects.hash(value);
}
@Override
public String toString() {
return value;
}
}값 객체는 다음과 같은 특성을 가집니다.
- 불변성: 생성 후 값을 변경할 수 없습니다.
- 값에 의한 동등성: 내부 값이 같으면 같은 객체로 취급합니다.
- 자가 검증: 생성 시점에 유효성을 검증합니다.
- 개념적 완전성: 관련된 속성과 동작을 하나로 묶습니다.
근데 이런 궁금증이 들 것입니다.
- "엔티티를 작성할 때 일반적으로 id를 Long 타입으로 선언했는데 왜 이렇게 객체로 만드는 거지?"
@Entity
public class Order {
@Id
private Long id; // 단순 원시 타입
// ...
}DDD에서는 조금 다릅니다.
- ID 자체가 "값 객체(Value Object)"로써 자체적인 의미와 행동을 갖습니다. 그래서 이런 식으로 정의합니다.
@Entity
public class Order {
@EmbeddedId // 또는 @Id + @Embedded도 가능
private OrderId id; // 값 객체로서의 ID
// ...
}참고로 @Embedded나 @EmbeddedId는 JPA에서 값 타입(Value Type)을 매핑할 때 사용하는 애노테이션입니다. 여기서 값 타입이란 독립적인 식별자가 없고, 소유 엔티티에 종속된 객체를 의미합니다.
실무에서 @Embedded와 ID 객체를 사용하는 이유
- 실무에서 가장 큰 장점은 타입 안전성입니다. 저는 실제로 id값을 잘못 넣어서 조회 오류가 발생한 적도 있습니다. 그래서 항상 id가 제대로 전달되었는지 확인하는 습관이 생겼습니다.
// 원시 타입 사용 시 - 위험!
public void processOrder(Long orderId, Long paymentId) {
// orderId와 paymentId를 실수로 바꿔 넣어도 컴파일러는 모름 😱
doSomething(paymentId, orderId); // 컴파일은 되지만 런타임 에러 발생 가능
}
// 값 객체 사용 시 - 안전!
public void processOrder(OrderId orderId, PaymentId paymentId) {
// 컴파일러가 타입 체크로 실수 방지 👍
doSomething(paymentId, orderId); // 컴파일 에러 발생!
}- 특히 프로젝트 규모가 커질수록 타입 안전성은 무시 못 할 가치가 있습니다. 코드도 점점 많아질 것이고 프로젝트가 전체적으로 복잡해지기 때문에 처음부터 ID 객체를 사용한다면 ID 혼동 버그를 사전에 예방할 수 있습니다.
ID를 객체로 사용하면 오버헤드가 있지 않나?
- 객체화시킨 ID 때문에 발생할 오버헤드에 대해서 고민하시는 분들이 계실 것이라고 생각합니다. 저는 약간의 성능 트레이드오프는 있을 것이지만 개발 생산성과 코드 안정성 향상이 그것을 상쇄하고도 남을 것이라고 생각합니다. 빠르게 개발하는 것보다 완성도 높고 안전하게 개발하는 것이 제 개인적인 원칙입니다.
마지막으로 ID를 통한 참조는 어떤 식으로 활용되는지 살펴봅시다.
- DDD에서는 애그리게잇 경계를 넘는 탐색(조회)은 ID를 통해서만 해야 한다고 권장합니다. 그래서 아래와 같이 ID를 꺼내서 조회하는 방식으로 코드가 작성될 것입니다. 이런 패턴을 사용하면 애그리게잇 간의 결합도를 낮추면서도 필요한 관계는 유지할 수 있습니다.
@Transactional
@Service
public class OrderService {
private final OrderRepository orderRepository;
private final PaymentRepository paymentRepository;
// 생성자 주입...
public OrderWithPaymentDto getOrderWithPayment(OrderId orderId) {
// 주문을 조회합니다. (Aggregate Root)
Order order = orderRepository.findById(orderId)
.orElseThrow(() -> new OrderNotFoundException(orderId));
// 주문 도메인 내부에 있는(참조된) PaymentId를 꺼냅니다.
PaymentId paymentId = order.getPaymentId();
if (paymentId != null) {
// 꺼낸 ID 객체로 Payment를 조회합니다. (Aggregate Root)
Payment payment = paymentRepository.findById(paymentId)
.orElseThrow(() -> new PaymentNotFoundException(paymentId));
return OrderWithPaymentDto.from(order, payment);
} else {
return OrderWithPaymentDto.fromOrderOnly(order);
}
}
}
애그리게잇 설계 시 마주치는 도전과 해결책
실무에서 애그리게잇을 설계 하면서 자주 마주치는 도전과 해결책을 공유하겠습니다.
애그리게잇 크기 결정
- 도전: 애그리게잇을 너무 크게 만들면 성능 문제가 발생하고, 너무 작게 만들면 일관성을 유지하기 어렵습니다.
- 해결책: 다음과 같은 질문들로 애그리게잇 크기를 결정하는 것을 추천합니다.
- 이 객체들이 항상 함께 로드되어야 하는가?
- 이 객체들 간에 강한 일관성이 필요한가?
- 이 객체들이 함께 변경되는가?
이 질문들에 대한 답이 '예'라면 같은 애그리게잇에 포함시키고, '아니요'라면 분리하는 것이 좋을 것이라 생각합니다.
애그리게잇 간 참조
- 도전: 다른 애그리게잇을 직접 참조하면 결합도가 높아지고, 로드 시 성능 문제가 발생할 수 있습니다.
- 해결책: 애그리게잇 간에는 ID로만 참조합니다. 예를 들어, 주문 애그리게잇은 고객 객체를 직접 참조하지 않고 CustomerId만 가지고 있습니다.
// 좋지 않은 방식 (직접 참조)
@ManyToOne
private Customer customer;
// 좋은 방식 (ID로만 참조)
@Embedded
private CustomerId customerId;
- 필요한 경우 도메인 서비스나 애플리케이션 서비스에서 관련 애그리게잇을 조회 하여 사용합니다. (위에 예시가 있습니다.)
일관성 경계 설정
- 도전: 여러 애그리게잇을 한 트랜잭션에서 수정해야 하는 경우가 있습니다.
- 해결책: 이벤트를 활용하여 결합도를 낮추면서 일관성을 유지할 수 있습니다. 예를 들어, 주문이 생성되면 OrderCreatedEvent를 발행하고, 이를 구독하는 재고 관리 시스템에서 재고를 감소시킬 수 있습니다. (MSA라면 Kafka or MQ를 활용)
// 주문 서비스
@Transactional
public OrderId createOrder(CreateOrderCommand command) {
// 주문을 생성한다. (Aggregate Root)
Order order = Order.createNew(command.getCustomerId(), command.getShippingAddress());
// 주문에 들어갈 아이템을 만들어서 추가한다. (Aggregate 내부 Entity)
for (OrderItemDto item : command.getItems()) {
order.addOrderItem(item.getProductId(), item.getProductName(),
item.getQuantity(), item.getUnitPrice());
}
// 주문 실행 후 저장
order.confirmOrder();
Order savedOrder = orderRepository.save(order);
// 이벤트 발행
eventPublisher.publish(new OrderCreatedEvent(savedOrder));
return savedOrder.getId();
}
// 재고 서비스 (이벤트 핸들러)
@EventListener
@Transactional
public void handleOrderCreatedEvent(OrderCreatedEvent event) {
// 이벤트에서 주문을 꺼낸다.
Order order = event.getOrder();
// 주문 내부에 있는 아이템을 반복문을 돌린다.
for (OrderItem item : order.getOrderItems()) {
// 아이템이 가진 상품ID로 상품을 조회한다.
Product product = productRepository.findById(item.getProductId())
.orElseThrow(() -> new ProductNotFoundException(item.getProductId()));
// 상품의 재고를 감소시키고 저장한다.
product.decreaseStock(item.getQuantity());
productRepository.save(product);
}
}- 이렇게 하면 주문과 재고라는 두 애그리게잇이 별도의 트랜잭션에서 처리되므로 결합도가 낮아집니다. 물론 이 접근 방식은 최종 일관성(Eventual Consistency)을 가정합니다.
성능 최적화
- 도전: 애그리게잇 설계에 충실하다 보면 N+1 쿼리 문제 등 성능 이슈가 발생할 수 있습니다.
- 해결책: CQRS(Command Query Responsibility Segregation) 패턴을 적용하여 명령(쓰기)과 쿼리(읽기)를 분리할 수 있습니다. 쓰기 모델은 도메인 중심으로 설계하고, 읽기 모델은 성능에 최적화된 구조로 설계합니다.
// 쓰기 모델 (도메인 중심)
@Service
public class OrderCommandService {
@Transactional
public OrderId createOrder(CreateOrderCommand command) {
// DDD 규칙을 따르는 풍부한 도메인 모델 사용
}
}
// 읽기 모델 (성능 최적화)
@Service
public class OrderQueryService {
@Transactional(readOnly = true)
public OrderDetailDto getOrderDetail(String orderId) {
// 직접 SQL 쿼리나 JPQL을 사용하여 조인된 결과를 한 번에 가져옴
return orderQueryRepository.findOrderDetail(orderId);
}
}
애그리게잇과 스프링 데이터 JPA 사용 패턴
애그리게잇 루트를 통한 저장
- 애그리게잇 내부 객체는 애그리게잇 루트를 통해서만 저장되어야 합니다. 이를 JPA에서 구현하는 방법은 다음과 같습니다.
@Transactional
public void processOrder(OrderId orderId,
List<OrderItemCommand> itemCommands) {
// 주문을 조회합니다. (Aggregate Root)
Order order = orderRepository.findById(orderId)
.orElseThrow(() -> new OrderNotFoundException(orderId));
// 주문 아이템을 추가합니다. (모든 변경은 애그리게잇 루트의 메서드를 통해 이루어짐)
itemCommands.forEach(cmd ->
order.addOrderItem(cmd.getProductId(), cmd.getProductName(),
cmd.getQuantity(), cmd.getUnitPrice()));
// 추가된 아이템이 모두 저장됩니다. (애그리게잇 루트만 저장하면 내부 객체들도 함께 저장됨)
orderRepository.save(order);
}- 이 패턴은 @OneToMany와 CascadeType.ALL을 사용하여 애그리게잇 루트를 저장할 때 하위 엔티티들도 함께 저장되도록 설정합니다.
지연 로딩(Lazy Loading)과 즉시 로딩(Eager Loading)
- 애그리게잇 내부 객체는 항상 함께 로드되어야 하므로, 지연 로딩(Lazy)보다는 즉시 로딩(Eager)을 사용하는 것이 좋습니다. 그러나 JPA의 기본 즉시 로딩은 N+1 쿼리 문제를 일으킬 수 있으므로 주의가 필요합니다.
// 좋은 방식: 필요한 모든 관계를 한 번에 로드
@Repository
public class JpaOrderRepository implements OrderRepository {
@PersistenceContext
private EntityManager em;
@Override
public Optional<Order> findById(OrderId orderId) {
return em.createQuery(
"select o from Order o " +
"left join fetch o.orderItems " +
"left join fetch o.orderDiscounts " +
"where o.id = :orderId", Order.class)
.setParameter("orderId", orderId)
.getResultStream()
.findFirst();
}
}- 이렇게 fetch join을 사용하면 한 번의 쿼리로 애그리게잇 전체를 로드할 수 있습니다.
마무리: 애그리게잇 설계의 핵심 교훈
제 경험이 아직은 부족한 편이지만 실무에서 얻은 교훈을 공유하며 마무리하겠습니다.
- 도메인 전문가와의 지속적인 협업이 필수적입니다.
- 기술적인 관점에서만 애그리게잇을 설계 하면 실제 비즈니스 요구사항과 괴리가 생길 수 있습니다. 특히 설계가 완료되었다고 끝나는 것이 아니고 지속적으로 도메인에 대한 토론과 지식탐구를 하며 발전시켜 나가는 것이 정말 중요합니다.
- 완벽함보다는 진화를 목표로 하세요.
- 초기에 모든 것을 완벽하게 설계하려고 하기보다는, 시스템이 성장함에 따라 지속적으로 리팩터링 하는 접근 방식이 더 효과적입니다.
- 트레이드오프를 인식하고 상황에 맞게 결정하세요.
- 항상 '정답'이 있는 것은 아닙니다. 때로는 DDD 원칙을 유연하게 적용하는 것이 필요합니다. (No Silver Bullet: 은탄환은 없다!)
- 작은 애그리게잇이 주는 이점을 과소평가하지 마세요.
- 처음에는 큰 애그리게잇이 단순해 보일 수 있지만, 시스템이 성장하면서 작은 애그리게잇의 이점이 분명해집니다. 그래서 개인적으로는 1개의 애그리게잇 내부에 여러 엔티티를 종속시키는것 보다는 1개의 엔티티에 여러개의 VO들을 가지도록 하는것을 선호합니다.
- 도메인 이벤트는 DDD의 강력한 도구입니다.
- 애그리게잇 간의 결합을 낮추면서도 복잡한 비즈니스 프로세스를 구현할 수 있게 해 줍니다.
"훌륭한 설계는 더 이상 뺄 것이 없을 때가 아니라, 더 이상 더할 것이 없을 때 완성된다." - 앙투안 드 생텍쥐페리
긴 글 읽어주셔서 감사합니다! 다음에는 DDD의 또 다른 핵심 개념인 '바운디드 컨텍스트'에 대해 다뤄보도록 하겠습니다.
'DDD' 카테고리의 다른 글
| 코드에 비즈니스의 가치를 담자 (0) | 2025.05.03 |
|---|---|
| [DDD] Aggregate 당 하나의 Repository, 과연 최선인가? (2) | 2025.04.19 |
| [DDD] 유비쿼터스 언어(Ubiquitous Language)의 중요성 (0) | 2024.12.28 |
| 화살표 if문을 DDD로 우아하게 리팩토링하기 (1) | 2024.10.29 |
| 스프링에서 도메인 객체를 사용하는 건에 대해 (6) | 2024.08.31 |