이번 포스트에서는 카프카의 메시지 포맷에 대해서 알아보자
📌 서론
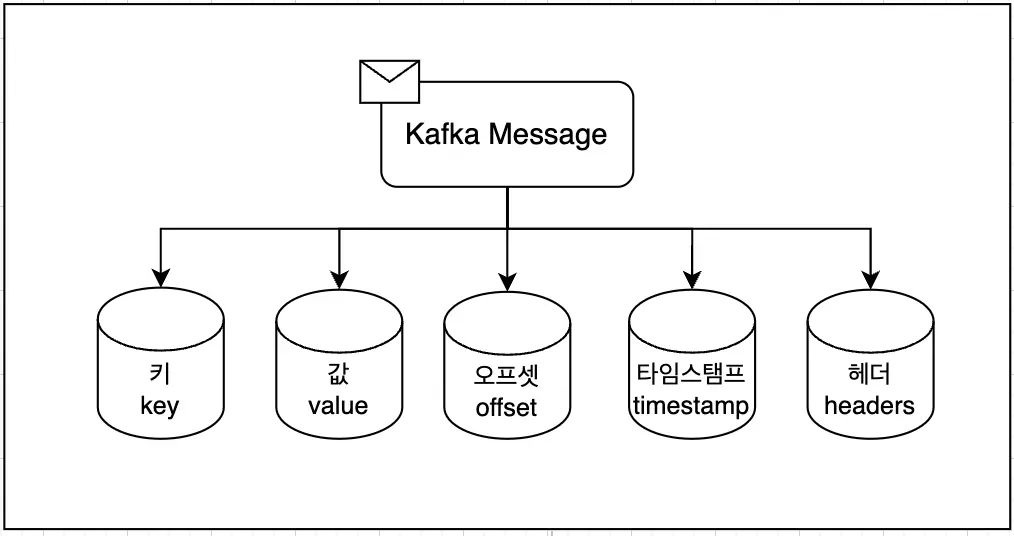
카프카 메시지는 데이터를 주고받는 데 사용되는 기본 단위다. 카프카를 이해하고 잘 사용하기 위해서는 이 메시지 구조를 잘 알아야 한다. 기본적으로, 카프카 메시지는 두 가지 주요 구성 요소를 가지고 있다. 예를 들어, 로그 데이터를 Kafka로 전송한다고 가정할 때, 각 로그의 '키'는 로그의 출처나 타입을 나타낼 수 있고, '값'은 실제 로그 내용이 될 수 있다. 이렇게 데이터를 구분하면 효율적으로 데이터를 관리하고 처리할 수 있다.
1. Kafka 메시지의 구조를 간단히 이해하기
Kafka 메시지의 기본 구조를 이해하는 것은 Kafka를 사용하는 데 있어서 가장 기본적이고 중요하다. 키와 값의 구조를 이해하면, Kafka가 데이터를 어떻게 처리하는지 더 잘 이해할 수 있다.
키(Key)
- 키는 메시지가 저장될 파티션을 결정하는 데 중요한 역할을 한다. 예를 들어 '과일'이라는 키에 '사과'라는 값을 연결하면, 카프카는 이 '사과'라는 데이터를 '과일'이라는 키와 관련된 파티션에 저장한다. 이렇게 키를 사용한다면 메시지를 특정 순서나 패턴으로 저장할 수 있기 때문에 데이터 처리에 있어서 더 효율적이다.
값(Value)
- 실제로 전송하고자 하는 데이터를 의미한다. 예를 들어 '사과', '바나나'와 같은 구체적인 데이터가 이 부분에 해당된다. 이 데이터는 카프카 시스템을 통해 전송되는 실제 정보로, 애플리케이션의 주요 데이터가 여기에 포함된다.

KafkaProducerConfig 클래스 (Kafka Producer 설정)
- 이 클래스는 카프카 메시지의 키와 값에 대한 직렬화 방법을 설정한다. 이는 카프카가 메시지를 파티션에 저장하고 관리하는 데 필수적인 부분이다. 즉, 코드에서 메시지의 기본 구조인 '키'와 '값'을 어떻게 처리하고 전송하는지를 보여준다.
- 코드를 자세히 보면 producerFactory() 메서드에서 Kafka 프로듀서의 필수 설정을 지정하고, KafkaTemplate을 통해 메시지 전송을 단순화한다.
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
// 카프카 서버의 주소를 설정
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 메시지의 '키'와 '값'에 대한 직렬화 방법 설정
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 프로듀서 팩토리 생성
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
// KafkaTemplate을 통해 메시지 전송을 단순화
return new KafkaTemplate<>(producerFactory());
}
}
KafkaProducerService 클래스 (Kafka Producer 서비스 레이어)
- 이 서비스 클래스는 KafkaTemplate을 사용하여 메시지를 Kafka 토픽에 전송하는 기능을 제공한다. sendMessage 메소드는 토픽과 메시지를 받아 Kafka에 전송한다. KafkaTemplate을 사용함으로써, 복잡한 카프카 API를 직접 다루는 대신, 간단하고 명확한 방법으로 메시지를 전송할 수 있다. 이는 카프카 메시지의 기본 구조를 이용하여 데이터를 효율적으로 전송하는 방법이다.
- 이 코드에서 Kafka의 기본 메시지 구조, 즉 '키'와 '값'은 StringSerializer를 통해 직렬화되며, KafkaTemplate을 사용해 실제로 메시지를 전송한다.
// lombok 사용
@RequiredArgsConstructor
@Service
public class KafkaProducerService {
private final KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String topic, String message) {
// KafkaTemplate을 사용하여 특정 토픽에 메시지 전송
kafkaTemplate.send(topic, message);
}
}
2. Kafka 메시지의 심화 구조
카프카 메시지는 단순히 데이터를 전송하는 역할만 하는 것이 아니라, 메시지의 상세한 정보를 제공하는 다양한 메타데이터를 포함할 수 있다. 이러한 메타데이터는 메시지 처리와 관리에 중요한 역할을 한다.
오프셋(Offset)
- Kafka에서 오프셋은 각 메시지가 파티션 내에서 어디에 위치하는지를 나타내는 고유 식별자다. 이는 Kafka가 메시지를 순서대로 정렬하고 관리하는 데 필수적이다.
- Kafka는 각 메시지의 순서를 오프셋을 통해 유지한다. 소비자(Consumer)는 이 오프셋을 사용하여 어떤 메시지를 이미 읽었는지, 현재 어디까지 읽고 있는지를 추적한다. 이는 특히 시스템 장애 발생 시 메시지 재처리 없이 처리를 재개할 수 있게 해주는 중요한 기능이다.
타임스탬프(Timestamp)
- 각 Kafka 메시지에는 생성된 시간이 타임스탬프로 기록된다. 이 정보는 메시지가 언제 생성되었는지를 나타낸다.
- 타임스탬프는 주로 시간 기반의 데이터 처리에 사용된다. 예를 들어, 메시지가 특정 시간 내에 유효한지 확인하거나, 시간 순서대로 메시지를 처리할 때 필요하다. 또한, 메시지의 유효성 검사에도 중요한 역할을 한다.
헤더(Headers)
- 헤더는 Kafka 메시지에 추가적인 정보나 메타데이터를 저장하는 공간이다. 이는 메시지의 내용 외에 추가적인 맥락을 제공한다.
- 헤더를 통해 메시지의 유형, 설명, 이벤트의 종류, 우선순위 등과 같은 메타데이터를 포함시킬 수 있다. 예를 들어, 시스템이 메시지를 다르게 처리해야 할 때 헤더의 정보를 기반으로 라우팅 하거나 필터링할 수 있다. 이는 메시지 기반의 시스템에서 유연성과 효율성을 크게 향상시킨다.
KafkaProducerConfig 클래스 (Kafka Producer 설정)
- 이 클래스는 카프카 프로듀서의 기본 설정을 정의한다. producerFactory() 메서드는 프로듀서의 필수 설정을 지정하며, KafkaTemplate을 통해 메시지 전송을 단순화한다.
- 여기서 StringSerializer는 키와 값에 대한 직렬화 방법을 설정하는 코드다. JsonSerializer를 사용함으로써 복잡한 객체도 JSON 형식으로 직렬화하여 카프카에 전송할 수 있다.
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); // JSON 직렬화 사용
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}KafkaProducerService 클래스 (Kafka Producer 서비스 레이어 - 스프링 부트 3)
- KafkaProducerService 클래스의 sendMessageWithHeaders 메서드는 카프카 메시지를 헤더와 함께 전송하는 방법을 보여준다. 이를 통해 메시지에 추가적인 메타데이터를 포함시킬 수 있다는 것을 알 수 있다.
- 아래의 코드에서처럼 헤더를 사용하면 메시지의 유형, 설명, 이벤트의 종류 등의 추가 정보도 제공할 수 있다. 이는 메시지 처리방식을 더 유연하게 만들어 준다.
// lombok 사용
@RequiredArgsConstructor
@Service
public class KafkaProducerService {
private final KafkaTemplate<String, Object> kafkaTemplate;
public void sendMessageWithHeaders(String topic, String key, Object value) {
Map<String, Object> headers = new HashMap<>();
headers.put("event-type", "user-login");
long timestamp = System.currentTimeMillis();
// 메시지와 헤더, 타임스탬프를 사용하여 메시지 전송
kafkaTemplate.send(topic, 0, timestamp, key, value, headers);
}
}
📌 잠깐! 왜 오프셋에 대한 코드는 없나요?
위의 KafkaProducerService 클래스 내부를 보면 타임스탬프에 대해서는 설정하고 있지만, 오프셋에 대한 명시적인 처리는 없다. 카프카에서 오프셋은 소비자(Consumer)가 메시지를 읽을 때 관리되므로, 프로듀서 측에서는 직접적으로 오프셋을 설정하는 것이 아니라 메시지를 전송할 때 카프카 시스템이 자동으로 관리한다. 따라서, 프로듀서의 코드에는 오프셋 관련 설정을 추가할 필요가 없으며, 주로 소비자 측에서 이를 활용한다.
'Apache Kafka' 카테고리의 다른 글
| [Kafka] SpringBoot3.x.x에서 Kafka 연동하기 (2) | 2024.02.18 |
|---|---|
| [Kafka] Docker로 Kafka 세팅하기 (Kraft 방식, M1 Mac) (2) | 2024.02.17 |
| Kafka(카프카)의 고가용성 및 대규모 데이터 처리방법 (5) | 2023.12.27 |
| Kafka(카프카) Producer(프로듀서)와 Consumer(컨슈머)의 동작 원리와 고가용성 (1) | 2023.12.27 |
| Kafka(카프카) 파티션(partition) 쉽게 이해하기 (5) | 2023.12.27 |