개발중 동시성 문제를 해결하기 위해 lock을 걸곤 한다. 이때 synchronized를 잘못된 위치에 사용하면 lock이 제대로 걸리지 않으니 주의하자.
📌 서론
자바와 스프링으로 서버를 개발하다 보면 synchronized를 사용해서 lock을 걸어본 경험이 있을 것이다.
또한 스프링 내부를 뜯어보다 보면 종종 synchronized를 사용한 코드들이 보인다. 나는 이것들에 대해 크게 신경 쓰지 않고 있었는데 이번에 인강으로 동시성 문제에 대한 공부를 하던 도중 새롭게 알게 된 사실이 있다.
바로 synchronized는 트랜잭션이 걸린 서비스 코드가 아닌 이 서비스 코드를 호출하는 컨트롤러에 걸어줘야만 동기화가 제대로 동작한다는 것이다.
지금부터 코드를 통해 왜 서비스에서 synchronized를 적용시켰을 때는 동시성 문제가 해결되지 않는 것인지 천천히 알아보도록 하자. 그리고 어떤 상황에 synchronized를 사용해야 할지 간단히 알아보자.
동시성 문제 해결 방법은 아래의 2가지 방법을 사용할 수도 있습니다!
[Java] 동시성 제어가 가능한 CopyOnWriteArrayList와 일반 ArrayList의 차이점
동시성 제어가 가능한 List인 CopyOnWriteArrayList를 알아보자📌 서론동시성 제어가 가능한 HashMap인 ConcurrentHashMap에 대해 공부하고 사용하다 보니 List에도 동시성 제어가 가능한 클래스가 존재할 것
curiousjinan.tistory.com
[Java] ConcurrentHashMap의 동작원리 (CAS 기법)
Java의 ConcurrentHashMap을 이해해 보자📌 서론Java에서 일반적인 HashMap을 사용하면 동시성 문제가 발생할 수 있다. HashMap은 멀티스레드 환경에서 안전하지 않기 때문에, 여러 스레드가 동시에 HashMap
curiousjinan.tistory.com
1. synchronized 동시성 문제 검증하기 (엔티티 작성)
우선 검증을 위해 필요한 코드를 작성해 보도록 하자
- 가장 먼저 엔티티를 선언했다.
- 기본적으로 id를 가지며 필드로는 data와 counter를 선언했다. (counter를 통해 동시성 문제를 발생시킬 예정이다.)
@NoArgsConstructor
@Getter
@Entity
public class SyncTestEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String data;
private int counter;
// 펙토리 메서드 생성을 위해 생성자는 private 선언
private SyncTestEntity(Long id, String data) {
this.id = id;
this.data = data;
this.counter = 0;
}
// factory method 선언
public static SyncTestEntity of(String data) {
return new SyncTestEntity(null, data);
}
// counter 증가 메서드
public void incrementCounter() {
this.counter++;
}
}factory method 이해하기
- 팩토리 메서드는 클래스 내부의 private 생성자에 접근하여 객체를 생성하는 역할을 한다. 이는 객체 생성 로직을 클래스 내부에 캡슐화하여 외부에서는 직접 접근할 수 없도록 하는 것이다. 따라서 팩토리 메서드는 클래스 내부의 private 생성자에 접근할 수 있는 우회 방법을 제공한다.
factory method 작성방법
- private 생성자를 선언하여 클래스 외부에서 직접 객체를 생성할 수 없도록 제한한다.
- 팩토리 메서드 (of, from 등)는 메서드 내부에서 같은 class의 private 생성자에 접근하여 객체를 생성하는 로직을 작성한다.
- 이렇게 하면 외부에서는 팩토리 메서드를 통해서만 객체를 생성할 수 있게 된다.
단위 테스트로 factory method의 동작 검증
- factory method 내부의 로직은 new SyncTestEntity(null, data)로 id에 대한 값은 따로 설정해주지 않는다. 그래도 id필드의 strategy로 "GenerationType"을 "IDENTITY"로 설정했다면 id값이 자동으로 생성되는지에 대한 여부를 테스트로 알아보자.
@SpringBootTest
class SyncTestEntityTest {
@Autowired
private SyncTestRepository syncTestRepository;
@DisplayName("factory method로 엔티티를 생성할때 메서드 내부에서 id를 null로 설정해도 엔티티가 정상적으로 생성되는지와 테이블에 id가 정상적으로 생성되는지 확인")
@Test
void testEntityCreation() {
//given
SyncTestEntity entity = SyncTestEntity.of("test data");
//when
SyncTestEntity savedEntity = syncTestRepository.save(entity);
//then
Assertions.assertThat(savedEntity.getId()).isNotNull();
Assertions.assertThat(savedEntity.getData()).isEqualTo("test data");
}
@DisplayName("factory method로 엔티티를 여러개 생성해서 저장할때 메서드 내부에서 id를 null로 설정해도 테이블에 id가 정상적으로 증가하여 저장되는지 확인")
@Test
void testEntityCreation2() {
//given
SyncTestEntity entity1 = SyncTestEntity.of("test data1");
SyncTestEntity entity2 = SyncTestEntity.of("test data2");
//when
SyncTestEntity savedEntity1 = syncTestRepository.save(entity1);
SyncTestEntity savedEntity2 = syncTestRepository.save(entity2);
//then
Assertions.assertThat(savedEntity1.getId()).isNotNull();
Assertions.assertThat(savedEntity2.getId()).isNotNull();
Assertions.assertThat(savedEntity1.getData()).isEqualTo("test data1");
Assertions.assertThat(savedEntity2.getData()).isEqualTo("test data2");
// id가 generatedValue로 생성되는 경우 id값이 서로 다르게 생성되는지 확인
Assertions.assertThat(savedEntity2.getId()).isNotEqualTo(savedEntity1.getId());
Assertions.assertThat(savedEntity2.getId()).isGreaterThan(savedEntity1.getId());
}
}
2. synchronized 동시성 문제 검증하기 (service, repository 작성)
Repository 로직을 작성해 보자
- 뭔가 추가할 것도 없다. 아주 간단히 JPA 리포지토리 인터페이스를 하나 생성해 주면 된다.
public interface SyncTestRepository extends JpaRepository<SyncTestEntity, Long> {
}Service 로직을 작성해 보자
- 서비스 로직에서는 데이터를 저장하는 addData() 메서드와 synchronized를 적용한 incrementCounter()와 적용하지 않은 incrementCounter() 메서드를 각각 생성해 줬다. (synchronized 적용에 대해서 비교하기 위함이다.)
@RequiredArgsConstructor
@Service
public class SyncTestService {
private final SyncTestRepository syncTestRepository;
/**
* 데이터를 저장한다.
*/
@Transactional
public void addData(String data) {
SyncTestEntity entity = SyncTestEntity.of(data);
syncTestRepository.save(entity);
}
/**
* synchronized 키워드를 사용하여 id에 해당하는 데이터의 counter를 1 증가시킨다.
*/
@Transactional
public void syncIncrementCounter(Long id) {
synchronized (this) {
SyncTestEntity entity = syncTestRepository.findById(id).orElseThrow();
entity.incrementCounter();
syncTestRepository.save(entity);
}
}
/**
* id에 해당하는 데이터의 counter를 1 증가시킨다.
*/
@Transactional
public void incrementCounter(Long id) {
SyncTestEntity entity = syncTestRepository.findById(id).orElseThrow();
entity.incrementCounter();
syncTestRepository.save(entity);
}
@Transactional(readOnly = true)
public List<SyncTestEntity> getAllData() {
return syncTestRepository.findAll();
}
}
3. synchronized 동시성 문제 검증하기 (controller 작성, 테스트 코드 작성)
Controller 로직을 작성해 보자
- 먼저 synchronized를 적용하지 않은 컨트롤러 class를 작성했다.
/**
* 데이터 동기화(synchronized)를 적용하지 않은 코드
*/
@RequestMapping("/not-synchronized-data")
@RequiredArgsConstructor
@RestController
public class NotSynchronizedDataController {
private final SyncTestService syncTestService;
@PostMapping("/add")
public ResponseEntity<Void> addData(@RequestBody String data) {
syncTestService.addData(data);
return ResponseEntity.ok().build();
}
@PostMapping("/increment")
public ResponseEntity<Void> incrementCounter(@RequestParam Long id) {
syncTestService.syncIncrementCounter(id);
return ResponseEntity.ok().build();
}
}- 다음으로 synchronized를 적용시킨 컨트롤러 class를 작성했다.
/**
* 데이터 동기화(synchronized)를 적용한 코드
*/
@RequestMapping("/synchronized-data")
@RequiredArgsConstructor
@RestController
public class SynchronizedDataController {
private final SyncTestService syncTestService;
@PostMapping("/add")
public synchronized ResponseEntity<Void> addData(@RequestBody String data) {
syncTestService.addData(data);
return ResponseEntity.ok().build();
}
@PostMapping("/increment")
public synchronized ResponseEntity<Void> incrementCounter(@RequestParam Long id) {
syncTestService.incrementCounter(id);
return ResponseEntity.ok().build();
}
}
어떤 것이 올바르게 동작할까?
- 이미 서론에서 말했지만 서비스 로직에서만 synchronized를 걸어줘서는 동시성 문제가 제대로 해결되지 않는다.
- 지금부터 테스트 코드를 통해 이것을 검증해 보도록 하자
테스트 코드 작성
- 총 2가지의 테스트를 진행한다. 하나는 컨트롤러에 synchronized를 적용한 엔드포인트를 호출하는 것이고 다른 하나는 서비스에만 synchronized를 적용한 엔드포인트를 호출하는 것이다.
- 이때 Thread는 10개로 지정했고 각 스레드가 200번의 요청을 보내도록 했다. 이렇게 설정했을 때는 10 * 200번 요청이 일어나야 하므로 동시성 제어가 잘 되었다면 총 2000번 counter가 증가하여 결과는 2000이 반환되어야 한다.
@SpringBootTest
@AutoConfigureMockMvc
class ControllerTest {
@Autowired
private MockMvc mockMvc;
@Autowired
private SyncTestRepository repository;
private ObjectMapper objectMapper = new ObjectMapper();
@BeforeEach
public void setup() throws Exception {
repository.deleteAll();
mockMvc.perform(post("/synchronized-data/add")
.contentType(MediaType.APPLICATION_JSON)
.content(objectMapper.writeValueAsString("InitialData")))
.andExpect(status().isOk());
}
@Test
@DisplayName("controller에서 동기화 제어를 하지 않을때 카운터 증가 - 카운터 값이 올바르지 않아야 함")
public void testIncrementCounterWithoutSynchronization() throws Exception {
// Given -> 테스트에 사용할 스레드 수와 각 스레드가 실행할 반복 횟수를 설정한다.
int threadCount = 10; // 총 10개의 스레드를 생성
int iterations = 200; // 각 스레드는 200번의 요청을 보내도록 설정
// CountDownLatch는 모든 스레드가 작업을 완료할 때까지 대기하는 데 사용된다.
// 초기 카운트를 스레드 수와 동일하게 설정하여 설정해준 모든 스레드가 작업을 완료할 때까지 대기할 수 있도록 한다. (10개의 스레드)
CountDownLatch latch = new CountDownLatch(threadCount);
// ExecutorService는 스레드 풀을 관리한다. 테스트를 위해 고정된 크기의 스레드 풀을 생성한다. (10개의 스레드)
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
// 각 스레드가 실행할 작업을 정의한다.
Runnable task = () -> {
for (int i = 0; i < iterations; i++) {
try {
// /not-synchronized-data/increment 엔드포인트에 요청을 보낸다.
// 이 엔드포인트는 컨트롤러에서 동기화(synchronized)되지 않은 상태에서 카운터를 증가시킨다.
mockMvc.perform(post("/not-synchronized-data/increment")
.param("id", "1"))
.andExpect(status().isOk());
} catch (Exception e) {
e.printStackTrace();
}
}
// 각 스레드가 작업을 완료할 때마다 호출하여 카운트를 1씩 감소시킨다. 만약 모든 스레드가 작업을 완료하면 카운트는 0이 된다.
latch.countDown();
};
// When -> 스레드 풀을 사용하여 위에서 정의한 작업(엔드포인트에 요청 보내기)을 실행한다.
for (int i = 0; i < threadCount; i++) {
executor.execute(task);
}
// CountDownLatch를 사용하여 모든 스레드가 작업을 완료할 때까지(카운트가 0이 될 때까지) 대기한다.
// 즉, 모든 스레드가 작업을 완료할 때까지 메인 스레드가 대기한다.
latch.await();
// 스레드 풀을 종료하고 모든 스레드가 종료될 때까지 기다린다.
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
// Then
// 데이터베이스에서 엔티티를 조회하고 카운터 값이 올바르게 증가하지 않았음을 확인한다.
SyncTestEntity entity = repository.findById(1L).orElseThrow();
// 동기화가 되지 않아 올바르게 증가하지 않을 가능성이 높다.
assertThat(entity.getCounter()).isNotEqualTo(threadCount * iterations);
System.out.println("Counter without synchronization: " + entity.getCounter());
}
@Test
@DisplayName("controller에서 동기화 제어를 하면서 카운터 증가 - 카운터 값이 올바르게 증가해야 함")
public void testIncrementCounterWithSynchronization() throws Exception {
// Given
// 테스트에 사용할 스레드 수와 각 스레드가 실행할 반복 횟수를 설정합니다.
int threadCount = 10; // 총 10개의 스레드를 생성합니다.
int iterations = 200; // 각 스레드는 200번의 요청을 보냅니다.
// CountDownLatch는 모든 스레드가 작업을 완료할 때까지 대기하는 데 사용됩니다.
CountDownLatch latch = new CountDownLatch(threadCount);
// ExecutorService는 스레드 풀을 관리합니다. 여기서는 고정된 크기의 스레드 풀을 생성합니다.
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
// 각 스레드가 실행할 작업을 정의합니다.
Runnable task = () -> {
for (int i = 0; i < iterations; i++) {
try {
// /synchronized-data/increment 엔드포인트에 요청을 보냅니다.
// 이 엔드포인트는 동기화된 상태에서 카운터를 증가시킵니다.
mockMvc.perform(post("/synchronized-data/increment")
.param("id", "1"))
.andExpect(status().isOk());
} catch (Exception e) {
e.printStackTrace();
}
}
// 작업이 완료되면 CountDownLatch의 카운터를 감소시킵니다.
latch.countDown();
};
// When
// 스레드 풀을 사용하여 작업을 실행합니다.
for (int i = 0; i < threadCount; i++) {
executor.execute(task);
}
// CountDownLatch를 사용하여 모든 스레드가 작업을 완료할 때까지 대기합니다.
latch.await();
// 스레드 풀을 종료하고 모든 스레드가 종료될 때까지 기다립니다.
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
// Then
// 데이터베이스에서 엔티티를 조회하고 카운터 값이 올바르게 증가했음을 확인합니다.
SyncTestEntity entity = repository.findById(1L).orElseThrow();
assertThat(entity.getCounter()).isEqualTo(threadCount * iterations); // 동기화가 되어 올바르게 증가해야 함
System.out.println("Counter with synchronization: " + entity.getCounter());
}
}
4. 테스트 상세 분석 (controller에서 synchronized를 사용하지 않을 때)
테스트를 분석해 보자
- 목적: 이 테스트는 컨트롤러에서 동기화 제어를 하지 않은 상태에서 멀티 스레드가 동시에 카운터 값을 증가시킬 때, 예상한 카운터 값이 올바르게 증가하지 않을 것임을 확인하는 테스트다.
테스트 과정 이해하기
- 멀티 스레드 환경에서 동시에 카운터 값을 증가시키는 요청을 보낸다.
- CountDownLatch를 사용하여 모든 스레드가 작업을 완료할 때까지 대기시킨다.
- 스레드 풀을 종료하고 모든 스레드가 종료될 때까지 기다린다.
- 데이터베이스에서 최종 카운터 값을 조회한다. (로그로 대체)
- 동기화가 제대로 동작하지 않았기 때문에 카운터 값이 예상한 값과 다를 것임을 검증한다. (2000이 나와야 하는데 더 적을 것이다.)
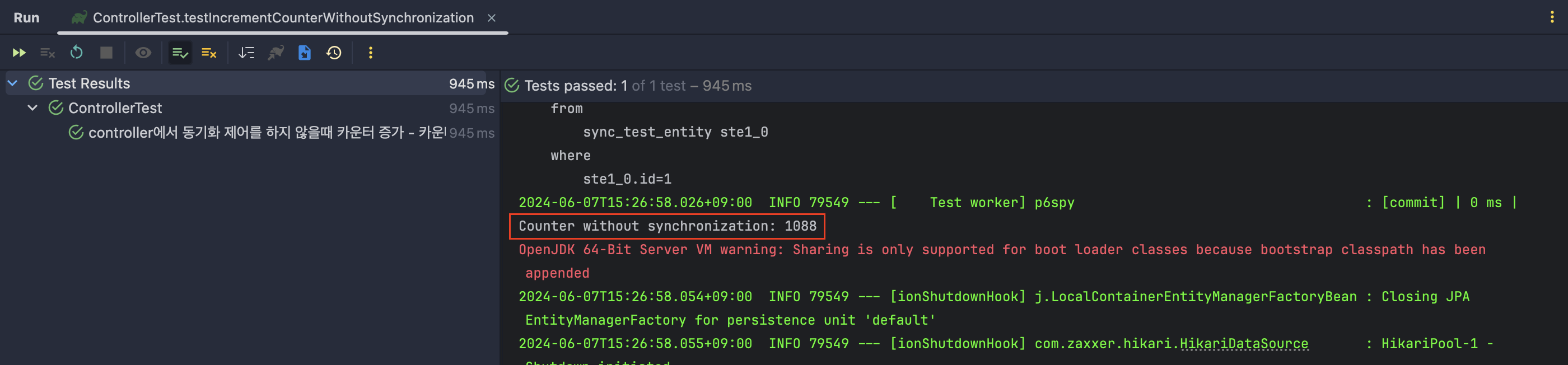
테스트 결과
- 사진이 조금 작아서 잘 안보일 수도 있지만 "Counter without synchronization"의 결과가 1088이 나온 것을 확인할 수 있다.
- 2000이 나와야 하지만 생각했던 것보다도 훨씬 더 적은 개수가 나왔다. 이것이 의미하는 것은 controller에서 동기화(synchronized) 제어를 하지 않았을 때는 동시성에 대한 제어가 제대로 되고 있지 않다는 것이다.
테스트 코드 확인하기
@Test
@DisplayName("controller에서 동기화 제어를 하지 않을때 카운터 증가 - 카운터 값이 올바르지 않아야 함")
public void testIncrementCounterWithoutSynchronization() throws Exception {
// Given -> 테스트에 사용할 스레드 수와 각 스레드가 실행할 반복 횟수를 설정한다.
int threadCount = 10; // 총 10개의 스레드를 생성
int iterations = 200; // 각 스레드는 200번의 요청을 보내도록 설정
// CountDownLatch는 모든 스레드가 작업을 완료할 때까지 대기하는 데 사용된다.
// 초기 카운트를 스레드 수와 동일하게 설정하여 설정해준 모든 스레드가 작업을 완료할 때까지 대기할 수 있도록 한다. (10개의 스레드)
CountDownLatch latch = new CountDownLatch(threadCount);
// ExecutorService는 스레드 풀을 관리한다. 테스트를 위해 고정된 크기의 스레드 풀을 생성한다. (10개의 스레드)
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
// 각 스레드가 실행할 작업을 정의한다.
Runnable task = () -> {
for (int i = 0; i < iterations; i++) {
try {
// /not-synchronized-data/increment 엔드포인트에 요청을 보낸다.
// 이 엔드포인트는 컨트롤러에서 동기화(synchronized)되지 않은 상태에서 카운터를 증가시킨다.
mockMvc.perform(post("/not-synchronized-data/increment")
.param("id", "1"))
.andExpect(status().isOk());
} catch (Exception e) {
e.printStackTrace();
}
}
// 각 스레드가 작업을 완료할 때마다 호출하여 카운트를 1씩 감소시킨다. 만약 모든 스레드가 작업을 완료하면 카운트는 0이 된다.
latch.countDown();
};
// When -> 스레드 풀을 사용하여 위에서 정의한 작업(엔드포인트에 요청 보내기)을 실행한다.
for (int i = 0; i < threadCount; i++) {
executor.execute(task);
}
// CountDownLatch를 사용하여 모든 스레드가 작업을 완료할 때까지(카운트가 0이 될 때까지) 대기한다.
// 즉, 모든 스레드가 작업을 완료할 때까지 메인 스레드가 대기한다.
latch.await();
// 스레드 풀을 종료하고 모든 스레드가 종료될 때까지 기다린다.
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
// Then
// 데이터베이스에서 엔티티를 조회하고 카운터 값이 올바르게 증가하지 않았음을 확인한다.
SyncTestEntity entity = repository.findById(1L).orElseThrow();
// 동기화가 되지 않아 올바르게 증가하지 않을 가능성이 높다.
assertThat(entity.getCounter()).isNotEqualTo(threadCount * iterations);
System.out.println("Counter without synchronization: " + entity.getCounter());
}
5. 테스트 상세 분석 (controller에서 synchronized를 사용할 때)
테스트 분석 (위와 동일)
- 목적: 이 테스트는 컨트롤러에서 동기화 제어를 하지 않은 상태에서 멀티 스레드가 동시에 카운터 값을 증가시킬 때, 예상한 카운터 값이 올바르게 증가하지 않을 것임을 확인하는 테스트다.
테스트 과정 이해하기 (위와 동일)
- 멀티 스레드 환경에서 카운터 값을 증가시키는 요청을 보낸다.
- CountDownLatch를 사용하여 모든 스레드가 작업을 완료할 때까지 대기한다.
- 스레드 풀을 종료하고 모든 스레드가 종료될 때까지 기다린다.
- 데이터베이스에서 최종 카운터 값을 조회한다. (로그로 대체)
- 동기화가 되어 카운터 값이 예상한 값과 일치하는지 검증한다.
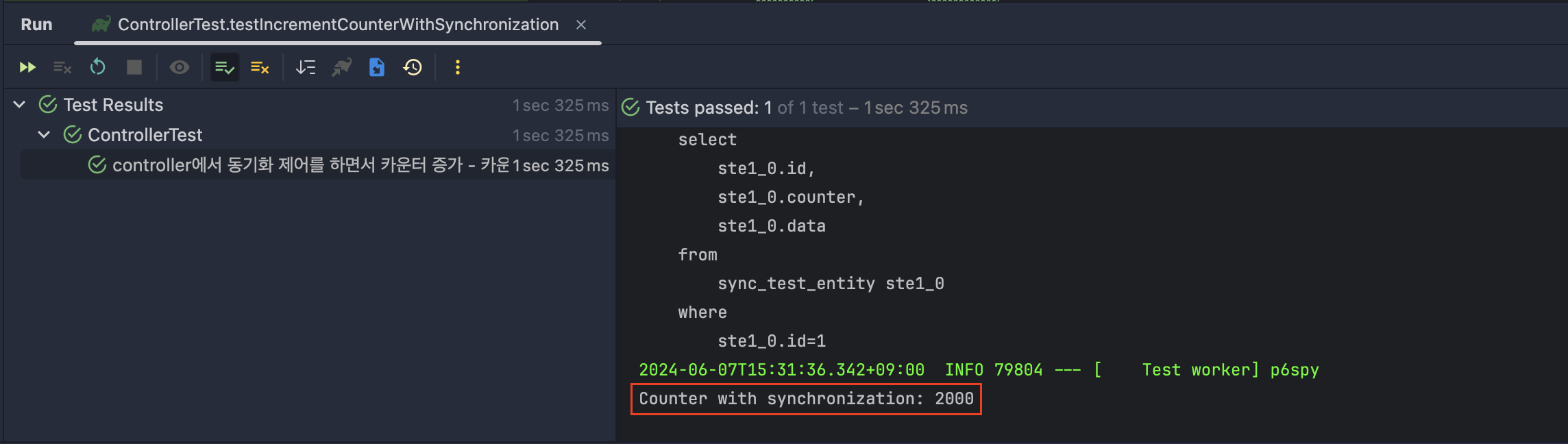
테스트 결과
- 사진이 조금 작아서 잘 안보일 수도 있지만 "Counter without synchronization"의 결과가 2000인 것을 확인할 수 있다.
- 이 테스트 결과가 의미하는 것은 컨트롤러에서 synchronized를 사용했을 때는 동시성 제어가 제대로 된다는 것이다.
테스트 코드 확인하기
@Test
@DisplayName("controller에서 동기화 제어를 하면서 카운터 증가 - 카운터 값이 올바르게 증가해야 함")
public void testIncrementCounterWithSynchronization() throws Exception {
// Given
// 테스트에 사용할 스레드 수와 각 스레드가 실행할 반복 횟수를 설정합니다.
int threadCount = 10; // 총 10개의 스레드를 생성합니다.
int iterations = 200; // 각 스레드는 200번의 요청을 보냅니다.
// CountDownLatch는 모든 스레드가 작업을 완료할 때까지 대기하는 데 사용됩니다.
CountDownLatch latch = new CountDownLatch(threadCount);
// ExecutorService는 스레드 풀을 관리합니다. 여기서는 고정된 크기의 스레드 풀을 생성합니다.
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
// 각 스레드가 실행할 작업을 정의합니다.
Runnable task = () -> {
for (int i = 0; i < iterations; i++) {
try {
// /synchronized-data/increment 엔드포인트에 요청을 보냅니다.
// 이 엔드포인트는 동기화된 상태에서 카운터를 증가시킵니다.
mockMvc.perform(post("/synchronized-data/increment")
.param("id", "1"))
.andExpect(status().isOk());
} catch (Exception e) {
e.printStackTrace();
}
}
// 작업이 완료되면 CountDownLatch의 카운터를 감소시킵니다.
latch.countDown();
};
// When
// 스레드 풀을 사용하여 작업을 실행합니다.
for (int i = 0; i < threadCount; i++) {
executor.execute(task);
}
// CountDownLatch를 사용하여 모든 스레드가 작업을 완료할 때까지 대기합니다.
latch.await();
// 스레드 풀을 종료하고 모든 스레드가 종료될 때까지 기다립니다.
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
// Then
// 데이터베이스에서 엔티티를 조회하고 카운터 값이 올바르게 증가했음을 확인합니다.
SyncTestEntity entity = repository.findById(1L).orElseThrow();
assertThat(entity.getCounter()).isEqualTo(threadCount * iterations); // 동기화가 되어 올바르게 증가해야 함
System.out.println("Counter with synchronization: " + entity.getCounter());
}
6. 서비스 로직에서 synchronized를 사용하면 동시성 문제가 발생하는 이유
서비스 로직 동작 원리 설명
@Transactional
public void syncIncrementCounter(Long id) {
synchronized (this) {
SyncTestEntity entity = syncTestRepository.findById(id).orElseThrow();
entity.incrementCounter();
syncTestRepository.save(entity);
}
}- 트랜잭션 시작: @Transactional 어노테이션에 의해 트랜잭션이 시작된다.
- synchronized로 lock 획득: synchronized (this) 블록에 의해 메서드에 대한 락을 획득하게 된다.
- 내부 로직 동작:
- findById(id)를 통해 데이터베이스에서 SyncTestEntity 엔티티를 조회한다.
- incrementCounter() 메서드를 호출하여 엔티티의 카운터를 증가시킨다.
- syncTestRepository.save(entity)를 호출하여 변경된 엔티티를 저장한다.
- lock 반납: synchronized 블록을 벗어나면서 락을 반납하게 된다.
- 트랜잭션 커밋: 메서드가 종료되면서 트랜잭션이 커밋된다.
서비스에서 synchronized를 사용하면 동시성 문제가 발생하는 이유
- 스레드 A가 syncIncrementCounter() 메서드를 호출:
- 트랜잭션을 시작하고, synchronized 블록에 들어가 락을 획득한다.
- 트랜잭션을 시작하고, synchronized 블록에 들어가 락을 획득한다.
- 스레드 A의 작업:
- findById(id)로 현재 카운터 값이 99인 엔티티를 조회한다. (여기서 id는 1이라고 가정).
- incrementCounter()를 호출하여 카운터를 100으로 증가시킨다.
- save(entity)를 호출하지만, 트랜잭션이 커밋되기 전이므로 데이터베이스에는 반영되지 않는다.
- 스레드 B가 syncIncrementCounter() 메서드를 호출:
- 스레드 A가 획득했던 락이 반납된 상태라 synchronized 블록에 들어가 락을 획득한다.
- 이때 아직 데이터베이스에는 스레드 A가 증가시킨 카운터가 반영되지 않은 상태이다.
- 스레드 B의 작업:
- findById(id)로 데이터를 조회한다.
- 이때 조회한 데이터는 스레드 A의 트랜잭션이 아직 커밋되지 않았기 때문에 카운터가 99다.
- incrementCounter()를 호출하여 카운터를 100으로 증가시킨다.
- save(entity)를 호출한다.
- 락을 반납한다.
- 스레드 A가 트랜잭션을 커밋:
- 스레드 B의 동작과 무관하게 스레드 A의 트랜잭션이 커밋되면서 카운터 값 100이 데이터베이스에 반영된다.
- 스레드 B의 동작과 무관하게 스레드 A의 트랜잭션이 커밋되면서 카운터 값 100이 데이터베이스에 반영된다.
- 스레드 B가 트랜잭션을 커밋:
- 스레드 B의 트랜잭션도 커밋되면서 카운터 값 100이 데이터베이스에 반영된다.
- 스레드 B의 트랜잭션도 커밋되면서 카운터 값 100이 데이터베이스에 반영된다.
결과
- 두 스레드 모두 카운터 값을 99에서 100으로 증가시켰기 때문에, 최종 카운터 값은 100이 된다.
- 정상적인 경우라면 최종 카운터 값은 101이 되어야 한다.
결론
- 이런 상황이 반복되면, 기대했던 2000번의 증가가 실제로는 더 적은 횟수로 반영될 수 있다.
- 또한 너무 많은 스레드가 동시에 동작하면 오히려 2000번보다 더 많은 결괏값을 받게 될 수도 있다.
- 동시성 문제로 인해 데이터 일관성이 깨지게 되는 것이다.
7. 근데 lock을 걸면 성능 저하가 있을 텐데? 어떻게 사용하는 것이 좋을까?
성능 저하를 최소화하기 위해 동기화를 적용하는 방법
- 특정 엔드포인트에 synchronized를 적용하는 것은 동시성 문제를 해결하는 한 가지 방법이다. 하지만, 이는 성능 저하를 유발할 수 있다. 따라서 동기화는 주로 다음과 같은 중요한 엔드포인트에만 적용하는 것이 좋다고 한다.
1. 이벤트 관련 엔드포인트 (선착순 이벤트)
- 이벤트 처리를 담당하는 엔드포인트에서는 데이터의 일관성을 유지하기 위해 동기화가 필요할 수 있다. 예를 들어, 한정된 수량의 쿠폰 발급, 재고 관리, 중요 데이터 업데이트 등의 경우이다.
2. 동기화가 필요한 특정 로직
- 동기화가 필요한 특정 로직이 있는 서비스나 메서드에만 synchronized를 적용할 수 있다. 예를 들어, 특정 조건을 만족하는 데이터의 원자적 업데이트가 필요한 경우이다.
성능 저하를 최소화하는 대안
1. ReentrantLock 사용
- synchronized 대신 ReentrantLock을 사용하면 더 세밀한 락 제어가 가능하다.
- 락 해제 여부, 대기 시간제한 등 다양한 기능을 제공하여 성능을 최적화할 수 있다.
2. 분산 락 사용
- Redis, Zookeeper와 같은 분산 락을 사용하여 여러 서버 인스턴스 간에 락을 관리한다.
- 이 방법은 분산 환경에서도 데이터 일관성을 유지할 수 있다.
3. 데이터베이스 트랜잭션
- 데이터베이스의 트랜잭션 격리 수준을 활용하여 동시성 문제를 해결할 수 있다.
- 행 락, 테이블 락 등을 사용하여 데이터의 일관성을 유지한다.
'Spring > Spring에서 Java 활용하기' 카테고리의 다른 글
| [Java] Enum NPE 문제 빠르게 해결하기 (feat. equals, switch, AttributeConverter) (0) | 2024.11.03 |
|---|---|
| [Java] 메서드 추출(Extract Method)로 복잡한 비즈니스 로직 개선하기 (0) | 2024.11.02 |
| [Spring] StackTrace 상세분석 (예외처리) (0) | 2024.03.30 |
| [Spring] 자바 리플렉션과 생성자 주입의 관계 (1) | 2023.11.19 |
| [Spring] 스프링은 추상화를 어떻게 적용했을까? (0) | 2023.11.02 |