Kotlin(Java)을 사용하여 일반 스레드의 성능을 비교해 보자
📌 서론
최근 나는 동시성 제어에 관심이 생겨 관련된 개념을 많이 찾아보고 생각하고 있다.
그래서 java의 동시성 제어 List, Map 등을 내부 구현까지 뜯어서 확인해보기도 하고 성능 테스트도 진행했다.
이렇게 열심히 테스트를 하다 보면 동시성 제어가 이런 것이구나! 깨달음을 얻게 된다. 근데 나는 궁금한 게 많은 개발자다 보니 테스트를 하며 새로운 것들에 눈을 뜨게 되었다.
특히 locust결과를 보면 알 수 있는 RPS(Requests Per Second)에 대해서 많이 궁금한 점이 생겼다. RPS는 동시성 제어(synchronized, concurrentHashMap)에 따라 lock이 걸리며 결과가 다르게 나타나기도 하지만 스레드의 'blocking, non-blocking'에 따라서도 다른 결과를 내보냈다.
그래서 나는 이것들의 기본이 되는 '스레드(Thread)'를 아는 것이 제일 중요하다고 생각하게 되었고 일주일간 매일매일 시간을 내서 테스트를 해보고 세미나도 보고 분석도 열심히 했다.
이번 포스팅은 Thread 시리즈로서 최소 4편 정도 예정되어 있다. 추후 코루틴(coroutine), 가상 스레드(virtual thread)에 대해서도 다룰 예정이니 내용을 기대해도 좋다. 이번 편은 시작으로서 가장 기본이 되는 '일반 스레드'를 사용하여 I/O, CPU 작업을 진행할 시 어떤 성능을 보여주는지 알아보도록 하자.
1. 테스트 환경
환경 설명
| 언어 | Kotlin (Java21) |
| 프레임워크 | SpringBoot3.x.x |
| 라이브러리 | 코루틴(core, reactor) |
| IDE | IntelliJ |
| AI tool | ChatGPT 4o, Claude3.5 Sonnet |
| 마음가짐 | 호기심, 참을성, 노력, 반복 |
플러그인과 버전은 다음과 같다.
plugins {
kotlin("jvm") version "1.9.25"
kotlin("plugin.spring") version "1.9.25"
id("org.springframework.boot") version "3.3.3"
id("io.spring.dependency-management") version "1.1.6"
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}build.gradle에 2개의 라이브러리를 추가했다. (코루틴)
// coroutines
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.8.1")
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-reactor")전체 코드 github 주소 (편하게 직접 테스트 해보시길 바랍니다.)
GitHub - wlsdks/Thread-study: 스레드에 대한 모든것을 알아보는 프로젝트
스레드에 대한 모든것을 알아보는 프로젝트. Contribute to wlsdks/Thread-study development by creating an account on GitHub.
github.com
2. 스레드 이해하기
스레드가 무엇인가?
- 스레드는 컴퓨터 프로그램이 동시에 여러 작업을 처리할 수 있도록 해주는 작업 단위다. 예를 들어, 프로그램이 파일을 다운로드하면서 동시에 화면에 이미지를 표시해야 한다면, 각각의 작업을 스레드로 처리한다. 이를 통해 프로그램은 중단 없이 여러 작업을 빠르고 효율적으로 수행할 수 있다.
- 쉽게 말해, 스레드는 여러 사람이 동시에 일을 나눠서 처리하는 것과 같다. 한 사람이 여러 작업을 순차적으로 처리하는 것보다, 여러 사람이 동시에 일하면 더 빠르게 완료할 수 있듯이, 스레드를 사용하면 컴퓨터가 여러 작업을 동시에 처리할 수 있게 된다.
멀티 스레드란?
- 멀티 스레드(Multi-threading)는 하나의 프로그램이 동시에 여러 작업을 처리할 수 있도록 여러 개의 스레드를 사용하는 기술이다. 각 스레드는 독립적으로 실행되며, 이를 통해 병렬로 작업을 처리함으로써 프로그램의 성능을 크게 향상시킬 수 있다. 예를 들어, 한 스레드가 파일을 다운로드하는 동안 다른 스레드가 사용자 입력을 처리하거나, 네트워크 요청을 수행하는 등 여러 작업을 동시에 처리하는 것이 가능하다.
- 그러나, 이러한 멀티 스레드 환경에서는 공유 자원에 대한 동기화가 필요하다. 여러 스레드가 동시에 같은 자원(예: 메모리, 변수)에 접근할 때 데이터 충돌이나 비일관성이 발생할 수 있기 때문이다. 이러한 충돌을 방지하기 위해 동기화(lock)를 사용하여 자원 접근을 제어한다. 이를 통해 경합(race condition)을 방지하고, 자원의 상태(state)를 일관성 있게 유지할 수 있다. 적절한 동기화를 통해 프로그램은 더욱 안정적이고 응답성이 높은 상태로 복잡한 작업을 효율적으로 처리할 수 있게 된다.
- 이러한 동기화 문제가 바로 우리가 '동시성 문제'라고 부르는 상황이다. 동시성 문제는 여러 스레드가 동시에 같은 자원에 접근할 때 발생하는 문제로, 데이터의 일관성이 깨지거나 예상치 못한 오류가 발생할 수 있다. 이는 특히 스프링에서 여러 API 요청이 동시에 발생하여, 해당 요청들이 같은 자원에 접근할 때 자주 나타난다. 예를 들어, 여러 사용자가 동시에 동일한 데이터베이스 엔티티를 업데이트하거나 조회할 때 경합이 발생할 수 있다.
- 이때 적절한 동기화가 이루어지지 않으면 경합 조건(race condition)이 발생하여, 데이터가 의도하지 않은 방식으로 변경되거나 일관성이 깨질 수 있다. 이를 해결하기 위해 동기화 메커니즘(예: synchronized 블록, 트랜잭션 관리, Lock 클래스 등)을 통해 상태를 관리해야 하며, 이를 통해 안정성과 데이터 일관성을 유지할 수 있다.
OS 레벨 스레드란? (플랫폼 스레드)
- OS 레벨 스레드(플랫폼 스레드)는 운영 체제가 직접 관리하는 스레드다. 각 스레드는 운영 체제의 스케줄러에 의해 관리되며, 운영 체제가 스레드에 CPU와 메모리 자원을 할당한다. 이러한 스레드는 CPU 코어와 직접 상호작용하며, 멀티코어 시스템에서는 여러 스레드가 병렬로 실행될 수 있다.
- 운영 체제는 자원을 관리하고, 여러 스레드를 동시에 실행할 수 있도록 최적화하여, CPU를 많이 사용하는 작업에서는 매우 효율적이다. OS 레벨 스레드는 복잡한 자원 관리와 스레드 스케줄링을 운영 체제가 자동으로 처리해 주기 때문에, 개발자는 이에 신경 쓰지 않고 병렬 처리를 쉽게 구현할 수 있다.
3. 스레드의 구조
diagram을 통해 스레드의 구조를 알아보자 (draw.io)
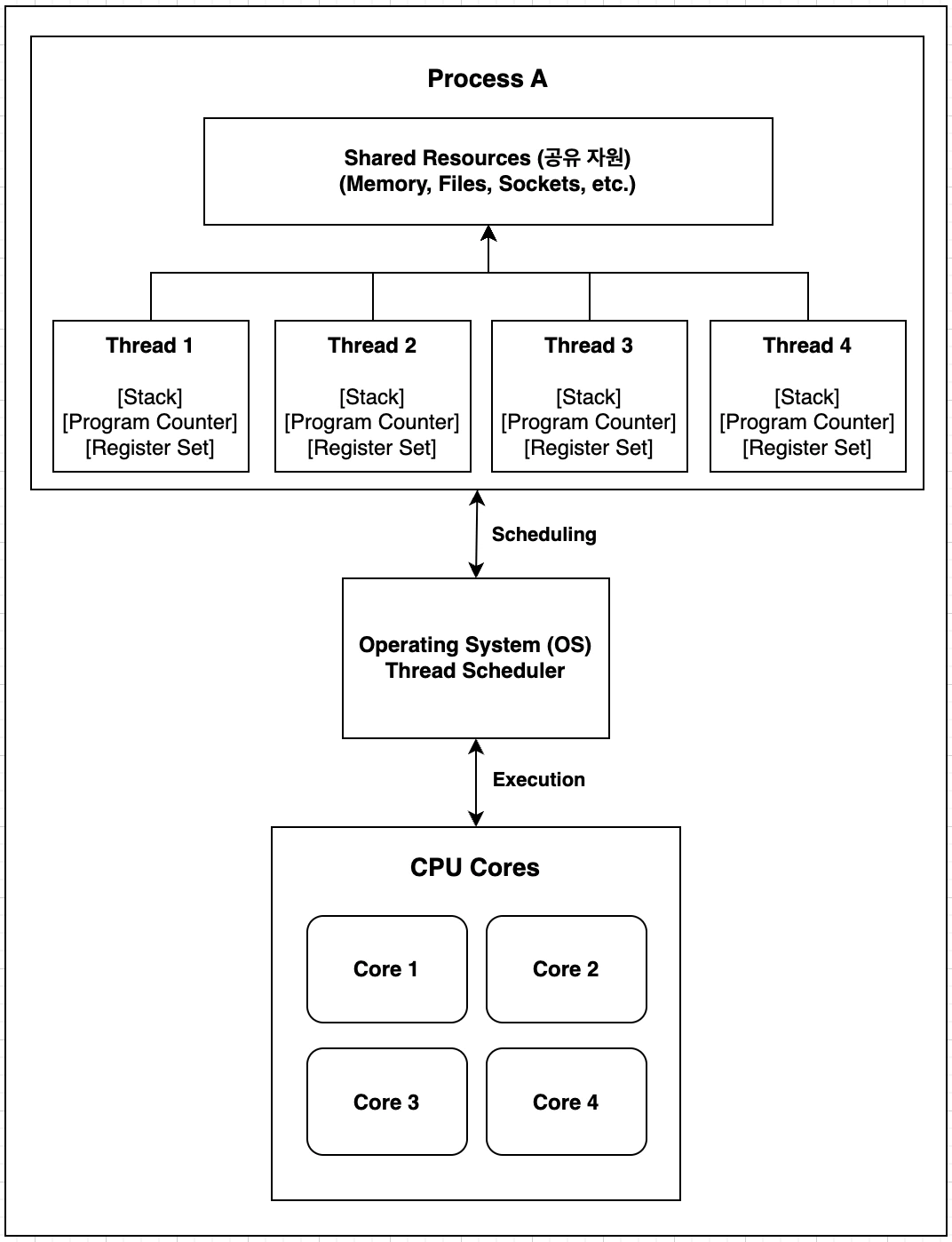
프로세스 (Process)
- Process는 실행 중인 프로그램의 '인스턴스'를 의미한다.
- Process는 다음과 같은 '특징'을 가진다.
- 독립된 메모리 공간과 시스템 자원을 할당받는다.
- 하나 이상의 스레드를 포함한다.
- 프로세스 내의 모든 스레드가 공유할 수 있는 자원(예: 메모리 영역, 파일 핸들)을 가진다.
- Process의 '예시'는 다음과 같다.
- 자바 애플리케이션 (java -jar myapp.jar로 실행되는 프로그램)
- 스프링 부트 애플리케이션 (java -jar spring-app.jar로 실행되는 웹 애플리케이션)
- 데이터베이스 서버 (예: MySQL, PostgreSQL)
- 웹 서버 (예: Apache Tomcat)
스레드
- 프로세스 내에 여러 스레드(Thread 1, 2, 3, 4)가 존재한다.
- 각 스레드는 공유 자원에 접근할 수 있다 (위쪽 화살표).
- 각 스레드는 자신만의 고유한 자원을 가진다:
- 스택: 지역 변수, 매개변수, 리턴 주소 등을 저장
- 프로그램 카운터: 현재 실행 중인 명령어의 주소를 가리킴
- 레지스터 세트(집합): 스레드의 실행 상태 정보를 저장
공유 자원
- 메모리, 파일, 소켓 등 프로세스 내의 모든 스레드가 공유하는 자원이다.
운영체제 스레드 스케줄러 (Operating System Thread Scheduler)
- 프로세스의 스레드와 CPU 코어 간 중재 역할을 수행한다.
- 다음과 같은 주요 기능을 담당한다.
- 프로세스 내의 스레드를 CPU 코어에 할당
- 각 스레드에 CPU 시간 분배
- 스레드 간 전환(컨텍스트 스위칭) 관리
- 어떤 스레드를 어떤 CPU 코어에서 실행할지 결정
CPU 코어
- 멀티코어 환경을 나타낸다. (다이어그램 예시: 4개의 코어)
- 스레드 실행 과정:
- '운영체제 스레드 스케줄러'가 실행할 '프로세스'의 특정 스레드를 선택
- 선택된 '프로세스의 스레드'의 컨텍스트(실행 상태 정보)를 CPU 코어에 로드
- 해당 '프로세스의 스레드'가 할당된 CPU 코어에서 직접 실행됨
4. 코드 작성 (일반: I/O, CPU 작업)
Tree 구조
└── src
├── main
│ ├── kotlin
│ │ └── com
│ │ └── study
│ │ └── thread
│ │ ├── ThreadApplication.kt
│ │ └── study
│ │ ├── Common.kt
│ │ └── RegularThread.kt
1편 이후부터 트리에 계속해서 kt파일이 추가될 것이다.
공통으로 사용하는 코드 (Common.kt)
- 상수, 함수를 정의해 둔 공통 사용 코드
package com.study.thread.study;
import kotlin.math.sin
// 테스트할 작업의 수
const val TEST_COUNT = 1000
const val THREAD_POOL_SIZE = 200
const val DELAY_MS = 10L // I/O 작업을 시뮬레이션하기 위한 지연 시간
// CPU 집중 작업을 시뮬레이션하는 함수 (모든 모델 공통)
fun simulateCPUIntensiveOperation() {
var result = 0.0
for (i in 1..1_000_000) {
result += sin(i.toDouble())
}
}
// 일반, 스레드 풀 작업 처리 결과를 출력하는 함수
fun printTestResult(result: TestResult) {
println("\n🧵 테스트 결과: ${result.testName}")
println("━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━")
println("📊 스레드 정보:")
println(" 🛫 시작 시 활성 스레드 수: ${result.initialThreadCount}")
println(" 🛬 종료 시 활성 스레드 수: ${result.finalThreadCount}")
println(" 📈 최대 동시 활성 스레드 수: ${result.maxActiveThreads}")
println(" 🔢 생성된 스레드 총 수: ${result.createdThreadsCount}")
println(" 🔚 (일반, 스레드 풀) 테스트 후 남아있는 스레드 수: ${result.remainingThreadsCount}")
println("\n📊 작업 처리 정보:")
println(" ✅ 완료된 작업 수: ${result.completedTasks}")
println(" ⏱️ 평균 작업 시간: ${"%.2f".format(result.avgTaskTime)} ms")
println(" 🏎️ 최소 작업 시간: ${result.minTaskTime} ms")
println(" 🐢 최대 작업 시간: ${result.maxTaskTime} ms")
println("\n📊 성능 지표:")
println(" ⏳ 총 실행 시간: ${result.executionTime} ms")
println(" 🚀 1초당 처리된 작업 수: ${"%.2f".format(result.completedTasks.toDouble() / (result.executionTime / 1000.0))}")
if (result.additionalInfo.isNotEmpty()) {
println("\n📌 추가 정보:")
result.additionalInfo.forEach { (key, value) ->
println(" • $key: $value")
}
}
println("━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━")
}
// 일반, 스레드 풀 작업 처리 결과를 저장하는 데이터 클래스
data class TestResult(
val testName: String,
val initialThreadCount: Int,
val finalThreadCount: Int,
val maxActiveThreads: Int,
val createdThreadsCount: Int,
val remainingThreadsCount: Int,
val completedTasks: Int,
val executionTime: Long,
val avgTaskTime: Double,
val minTaskTime: Long,
val maxTaskTime: Long,
val additionalInfo: Map<String, String> = emptyMap()
)
// 활성화된 스레드 수를 계산하는 함수 (일반 , 스레드 풀)
fun countActiveThreads(createdThreads: Set<Long>): Int {
return Thread.getAllStackTraces().keys.count { it.id in createdThreads }
}일반 스레드 테스트를 위한 코드 작성 (RegularThread.kt)
package com.study.thread.study;
import java.util.concurrent.ConcurrentHashMap
import java.util.concurrent.ConcurrentLinkedQueue
import java.util.concurrent.atomic.AtomicInteger
import kotlin.system.measureTimeMillis
fun main() {
// val regularThreadIoResult = testIOIntensiveThreads()
// printTestResult(regularThreadIoResult)
val regularThreadCpuResult = testCPUIntensiveThreads()
printTestResult(regularThreadCpuResult)
}
// 파일 작업을 시뮬레이션하는 함수 (일반 함수)
fun simulateFileOperation(fileName: String) {
Thread.sleep(DELAY_MS) // I/O 작업 시뮬레이션
}
// 일반 스레드 I/O 집중 작업 테스트
fun testIOIntensiveThreads(): TestResult {
val initialThreadCount = Thread.activeCount()
val tasksCompleted = AtomicInteger(0)
val createdThreads = ConcurrentHashMap.newKeySet<Long>()
val maxActiveThreads = AtomicInteger(0)
val taskTimes = ConcurrentLinkedQueue<Long>()
val threadTime = measureTimeMillis {
val threads = List(TEST_COUNT) {
Thread {
createdThreads.add(Thread.currentThread().id)
maxActiveThreads.updateAndGet { max -> maxOf(max, Thread.activeCount()) }
val taskStartTime = System.nanoTime()
simulateFileOperation("thread_file_$it.txt")
val taskEndTime = System.nanoTime()
taskTimes.add((taskEndTime - taskStartTime) / 1_000_000)
tasksCompleted.incrementAndGet()
}
}
threads.forEach { it.start() }
threads.forEach { it.join() }
}
Thread.sleep(100) // 스레드 종료 대기
val finalThreadCount = Thread.activeCount()
val remainingNewThreads = countActiveThreads(createdThreads)
return TestResult(
testName = "일반 스레드 I/O 집중 작업 테스트",
initialThreadCount = initialThreadCount,
finalThreadCount = finalThreadCount,
maxActiveThreads = maxActiveThreads.get(),
createdThreadsCount = createdThreads.size,
remainingThreadsCount = remainingNewThreads,
completedTasks = tasksCompleted.get(),
executionTime = threadTime,
avgTaskTime = taskTimes.average(),
minTaskTime = taskTimes.minOrNull() ?: 0,
maxTaskTime = taskTimes.maxOrNull() ?: 0
)
}
// 일반 스레드 CPU 집중 작업 테스트
fun testCPUIntensiveThreads(): TestResult {
val initialThreadCount = Thread.activeCount()
val tasksCompleted = AtomicInteger(0)
val createdThreads = ConcurrentHashMap.newKeySet<Long>()
val maxActiveThreads = AtomicInteger(0)
val taskTimes = ConcurrentLinkedQueue<Long>()
val threadTime = measureTimeMillis {
val threads = List(TEST_COUNT) {
Thread {
createdThreads.add(Thread.currentThread().id)
maxActiveThreads.updateAndGet { max -> maxOf(max, Thread.activeCount()) }
val taskStartTime = System.nanoTime()
simulateCPUIntensiveOperation()
val taskEndTime = System.nanoTime()
taskTimes.add((taskEndTime - taskStartTime) / 1_000_000)
tasksCompleted.incrementAndGet()
}
}
threads.forEach { it.start() }
threads.forEach { it.join() }
}
Thread.sleep(100) // 스레드 종료 대기
val finalThreadCount = Thread.activeCount()
val remainingNewThreads = countActiveThreads(createdThreads)
return TestResult(
testName = "일반 스레드 CPU 집중 작업 테스트",
initialThreadCount = initialThreadCount,
finalThreadCount = finalThreadCount,
maxActiveThreads = maxActiveThreads.get(),
createdThreadsCount = createdThreads.size,
remainingThreadsCount = remainingNewThreads,
completedTasks = tasksCompleted.get(),
executionTime = threadTime,
avgTaskTime = taskTimes.average(),
minTaskTime = taskTimes.minOrNull() ?: 0,
maxTaskTime = taskTimes.maxOrNull() ?: 0
)
}
5. 일반 스레드 I/O, CPU 테스트 진행
테스트 설정하는 방법
- Common.kt에 선언된 아래의 상수를 통해 테스트 횟수를 조정할 수 있다.
// 테스트할 작업의 수
const val TEST_COUNT = 1000
const val THREAD_POOL_SIZE = 200
const val DELAY_MS = 10L // I/O 작업을 시뮬레이션하기 위한 지연 시간일반 스레드 I/O 집중 작업을 하는 테스트를 살펴보자
- List(FILE_COUNT): 이 부분은 FILE_COUNT(1000) 크기의 리스트를 생성한다.
- { }: 이 중괄호 안에 있는 코드는 리스트의 각 요소를 초기화하는 람다 함수다.
- 이 람다 함수는 리스트의 각 인덱스(0부터 FILE_COUNT - 1까지)에 대해 한 번씩 호출된다.
val threadTime = measureTimeMillis {
val threads = List(TEST_COUNT) {
Thread {
createdThreads.add(Thread.currentThread().id)
maxActiveThreads.updateAndGet { max -> maxOf(max, Thread.activeCount()) }
val taskStartTime = System.nanoTime()
// 여기서 I/O작업 함수를 호출한다.
simulateFileOperation("thread_file_$it.txt")
val taskEndTime = System.nanoTime()
taskTimes.add((taskEndTime - taskStartTime) / 1_000_000)
tasksCompleted.incrementAndGet()
}
}
threads.forEach { it.start() }
threads.forEach { it.join() }
}따라서, 이 구문은 다음과 같이 동작한다.
- FILE_COUNT(1000)만큼 반복한다.
- 각 반복마다 { } 안의 코드를 실행한다.
- 각 실행의 결과가 리스트의 요소가 된다.
- 이 테스트의 경우, { } 안의 코드는 새로운 Thread 객체를 생성한다.
- 따라서 이 구문은 1000개의 Thread 객체를 포함하는 리스트를 생성한다.
핵심적인 부분
- 위의 작업 코드를 자세히 살펴보면 매번 simulateFileOperation()을 호출한다.
simulateFileOperation("thread_file_$it.txt")- 이 함수는 파일 작업을 시뮬레이션하는 함수다. 설정한(10L)만큼 스레드를 sleep 시킨다.
// 파일 작업을 시뮬레이션하는 함수 (일반 함수)
fun simulateFileOperation(fileName: String) {
Thread.sleep(DELAY_MS) // I/O 작업 시뮬레이션
}I/O 테스트 결과는 다음과 같다.
- 작업이 완료되는데 63ms가 걸렸다.
🧵 테스트 결과: 일반 스레드 I/O 집중 작업 테스트
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 스레드 정보:
🛫 시작 시 활성 스레드 수: 2
🛬 종료 시 활성 스레드 수: 2
📈 최대 동시 활성 스레드 수: 443
🔢 생성된 스레드 총 수: 1000
🔚 (일반, 스레드 풀) 테스트 후 남아있는 스레드 수: 0
📊 작업 처리 정보:
✅ 완료된 작업 수: 1000
⏱️ 평균 작업 시간: 11.44 ms
🏎️ 최소 작업 시간: 10 ms
🐢 최대 작업 시간: 23 ms
📊 성능 지표:
⏳ 총 실행 시간: 63 ms
🚀 1초당 처리된 작업 수: 15873.02
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━이제 CPU 테스트를 해보자
- CPU테스트는 기존과 같은 내부에서 호출하는 함수만 변경된다.
val threadTime = measureTimeMillis {
val threads = List(TEST_COUNT) {
Thread {
createdThreads.add(Thread.currentThread().id)
maxActiveThreads.updateAndGet { max -> maxOf(max, Thread.activeCount()) }
val taskStartTime = System.nanoTime()
// 여기서 CPU작업 함수를 호출한다.
simulateCPUIntensiveOperation()
val taskEndTime = System.nanoTime()
taskTimes.add((taskEndTime - taskStartTime) / 1_000_000)
tasksCompleted.incrementAndGet()
}
}
threads.forEach { it.start() }
threads.forEach { it.join() }
}- 내부의 함수가 아래의 CPU 전용 함수로 변경된다.
simulateCPUIntensiveOperation()- 이 함수를 통해 1부터 1,000,000까지의 수에 대해 sin() 함수를 호출하고, 그 결과를 변수 result에 누적하여 CPU 자원을 많이 소모하게 만든다.
// CPU 집중 작업을 시뮬레이션하는 함수 (모든 모델 공통)
fun simulateCPUIntensiveOperation() {
var result = 0.0
for (i in 1..1_000_000) {
result += sin(i.toDouble())
}
}CPU 테스트 결과는 다음과 같다.
- 작업이 완료되는데 694ms가 걸렸다.
🧵 테스트 결과: 일반 스레드 CPU 집중 작업 테스트
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 스레드 정보:
🛫 시작 시 활성 스레드 수: 2
🛬 종료 시 활성 스레드 수: 2
📈 최대 동시 활성 스레드 수: 41
🔢 생성된 스레드 총 수: 1000
🔚 (일반, 스레드 풀) 테스트 후 남아있는 스레드 수: 0
📊 작업 처리 정보:
✅ 완료된 작업 수: 1000
⏱️ 평균 작업 시간: 7.72 ms
🏎️ 최소 작업 시간: 5 ms
🐢 최대 작업 시간: 54 ms
📊 성능 지표:
⏳ 총 실행 시간: 694 ms
🚀 1초당 처리된 작업 수: 1440.92
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
열심히 테스트했으니 이제 분석을 해보자!
6. 일반 스레드 I/O, CPU 테스트 결과 분석
최대 동시 활성화된 스레드란?
- 동시 활성화된 스레드는 그 시점에 CPU에 의해 실행되거나 스케줄링 대기 중인 스레드들을 의미한다. 즉, 새로운 스레드가 실행 중이면서 기존 스레드가 완료되지 않으면 동시 활성 스레드로 처리된다.
스레드 정보
- I/O 집중 작업: 최대 443개의 스레드가 활성화됨. 이는 I/O 작업에서 스레드 대기 시간이 많아 더 많은 스레드를 필요로 하기 때문이다.
- CPU 집중 작업: 41개의 스레드만 활성화됨. CPU 작업은 각 스레드가 실행되면 CPU 자원을 지속적으로 사용하므로 적은 수의 스레드로 충분히 처리할 수 있다.
- I/O 작업은 대기 시간이 길어 많은 스레드가 필요하지만, CPU 작업은 계속 계산을 진행하므로 적은 스레드로도 작업을 처리할 수 있다.
성능 지표
- 총 실행 시간에서 큰 차이를 보인다. I/O 집중 작업(63 ms)이 CPU 집중 작업(694 ms) 보다 훨씬 빠르다.
- 1초당 처리된 작업 수에서도 I/O 집중 작업(15873.02)이 CPU 집중 작업(1440.92)보다 약 11배 높은 처리량을 보인다.
분석
- 동시성 처리: I/O 집중 작업에서 더 많은 스레드가 동시에 활성화될 수 있었다. 이는 I/O 작업이 대기 시간을 가지므로, 그동안 다른 스레드가 실행될 수 있기 때문이다.
- 작업 시간 안정성: I/O 집중 작업은 작업 시간이 더 일정한 반면, CPU 집중 작업은 변동이 크다는 것을 알 수 있다. 이는 I/O 작업이 주로 고정된 대기 시간에 의존하는 반면, CPU 작업은 시스템 부하에 따라 변동이 크기 때문인 것 같다.
- 전체 성능: I/O 집중 작업이 훨씬 빠른 총 실행 시간과 높은 처리량을 보인다. 이는 I/O 작업의 대기 시간 동안 다른 스레드가 실행될 수 있어 전체적인 병렬 처리가 더 효율적으로 이루어졌기 때문이다.
결론
- I/O 집중 작업과 CPU 집중 작업은 동시성 처리에 있어 상이한 특성을 보인다. I/O 집중 작업은 대기 시간이 많다 보니 여러 스레드를 효율적으로 활용할 수 있어 높은 동시성과 빠른 전체 처리 속도를 달성한다. 반면, CPU 집중 작업은 지속적으로 CPU를 사용하며 작업 완료까지 CPU를 점유하기 때문에, 실제 CPU 코어 수에 제한되어 상대적으로 느린 처리 속도를 보인다.
- 테스트 결과에서 볼 수 있듯이, I/O 작업은 최대 443개의 동시 활성 스레드를 활용하여 63ms 만에 작업을 완료했지만, CPU 작업은 최대 41개의 스레드만을 효과적으로 사용하여 694ms가 소요되었다. 이는 I/O 작업이 대기 시간을 활용해 다른 스레드를 실행할 수 있는 반면, CPU 작업은 각 스레드가 작업을 마칠 때까지 CPU를 점유하기 때문이다.
- 만약 물리적 CPU 코어 수를 초과하는 스레드가 동시에 실행되려 하면 운영 체제의 스케줄러는 각 스레드에 CPU 시간을 할당한다. 이 과정에서 발생하는 '컨텍스트 스위칭'은 추가적인 오버헤드를 유발한다. 이로 인해 CPU 집중 작업에서 과도한 스레드 사용은 오히려 성능 저하를 초래할 수 있다. 반면 I/O 작업은 많은 스레드가 대기 상태에 있기 때문에, 물리적 CPU 코어 수보다 많은 스레드를 효율적으로 관리할 수 있다.
마무리
- 결론적으로, 작업의 특성을 정확히 파악하고 그에 맞는 동시성 전략을 선택하는 것이 중요하다. I/O 집중 작업에서는 많은 스레드를 활용하여 대기 시간을 최소화하고, CPU 집중 작업에서는 CPU 코어 수에 맞춘 최적의 스레드 수를 유지하여 효율성을 극대화해야 한다. 또한, 실제 환경에서는 지속적인 모니터링과 튜닝을 통해 최적의 성능을 달성할 수 있도록 해야 한다.
이번에는 일반 스레드를 사용해서 I/O, CPU 작업에 대한 성능 테스트를 해봤다. 2탄에서는 스레드풀을 사용하여 테스트를 해본 뒤 일반 스레드와의 차이점까지 알아보도록 하자
아래의 2탄을 읽어보자
[Thread] 2. 스레드풀의 I/O, CPU 성능 비교
Kotlin(Java)을 사용하여 스레드풀의 성능을 비교해 보자📌 서론지난 포스트에서는 일반적인 스레드 환경의 I/O, CPU 스레드 성능을 비교해 봤다.이번 포스트는 Thread 시리즈의 2번째 포스트로서 만
curiousjinan.tistory.com
'개발지식 > 스레드(Thread)' 카테고리의 다른 글
| [Thread] 코루틴(Coroutine)의 동시성 제어 (0) | 2024.09.22 |
|---|---|
| [Thread] 코루틴(Coroutine)의 예외처리 (0) | 2024.09.22 |
| [Thread] 4. Kotlin의 코루틴(Coroutine)이란? (1) | 2024.09.19 |
| [Thread] 3. 일반 스레드 vs 스레드풀 (I/O, CPU 성능 비교) (2) | 2024.09.16 |
| [Thread] 2. 스레드풀의 I/O, CPU 성능 비교 (2) | 2024.09.15 |