SpringBoot3.x.x 에서 JPA로그 추적을 위한 P6Spy 적용을 해보자
1. SpringBoot 프로젝트 내부에 P6spy를 적용시키는 이유
P6Spy를 사용하는 주된 이유는 스프링 부트와 JPA를 사용하는 프로젝트에서 SQL 쿼리를 정확하고 효과적으로 로깅하고 추적하기 위해서다. P6Spy는 아래의 3가지 상황에서 중요하게 사용된다.
- 쿼리 확인
- JPA는 매우 편리하지만, 개발자가 직접 쿼리를 작성하지 않기 때문에 실제 어떤 쿼리가 실행되는지 확인하기 어렵다. P6Spy를 사용하면 이러한 쿼리를 눈으로 직접 확인할 수 있다. 특히 의도한 대로 작동하지 않을 때나 N+1 문제가 발생했는지 확인이 필요할 때 유용하다.
- JPA는 매우 편리하지만, 개발자가 직접 쿼리를 작성하지 않기 때문에 실제 어떤 쿼리가 실행되는지 확인하기 어렵다. P6Spy를 사용하면 이러한 쿼리를 눈으로 직접 확인할 수 있다. 특히 의도한 대로 작동하지 않을 때나 N+1 문제가 발생했는지 확인이 필요할 때 유용하다.
- 프록시를 통한 로깅
- P6Spy는 기존 어플리케이션의 코드를 변경하지 않고도 데이터베이스의 데이터를 가로채고 로그를 남길 수 있는 프레임워크다. 사용자의 DataSource를 P6SpyDataSource가 감싸고, JDBC 요청이 발생할 때마다 P6Spy가 프록시로 래핑하여 해당 정보를 분석하고 로그를 남기는 방식으로 작동한다.
- P6Spy는 기존 어플리케이션의 코드를 변경하지 않고도 데이터베이스의 데이터를 가로채고 로그를 남길 수 있는 프레임워크다. 사용자의 DataSource를 P6SpyDataSource가 감싸고, JDBC 요청이 발생할 때마다 P6Spy가 프록시로 래핑하여 해당 정보를 분석하고 로그를 남기는 방식으로 작동한다.
- 외부 라이브러리의 장점
- P6Spy는 JPA나 Hibernate에서 제공하는 SQL 로깅 기능 대신 사용할 수 있는 오픈 소스, 무료 라이브러리로, Java 어플리케이션에서 SQL 로그를 가로채는데 유용하다. 이는 다양한 방법으로 애플리케이션에 통합할 수 있으며, 스프링 부트 어플리케이션에서 P6Spy를 사용하는 예제를 통해 주요 구성 옵션을 볼 수 있다.
내가 p6spy를 적용시킨 이유는 1번 "쿼리 확인"에 해당했다. 나는 JPA를 사용 중인데 내가 실행시킨 로직에서 동작하는 JPA의 쿼리를 분석하려고 했더니 아래와 같이 쿼리가 제대로 보이지 않아서 P6spy를 설정하게 되었다. 문제는 SpringBoot3라서 그런지 약간 설정방법이 달라졌다는 것이었다.

2. SpringBoot3.x.x에서 P6spy 적용방법이 바뀐 이유
2-1. SpringBoot3부터 적용방법이 변경된 이유
스프링 부트 3에서 P6Spy 적용 방법이 바뀐 건 스프링 부트의 자동 설정(auto-configuration) 방식이 변화했기 때문이다. 스프링 부트 3에서는 데이터 소스를 꾸미는(decorating) 작업을 위해 특별한 프로젝트인 'gavlyukovskiy/spring-boot-data-source-decorator'를 사용한다.
이 프로젝트는 P6Spy 같은 데이터 소스 데코레이터를 쉽게 통합할 수 있게 해주는 역할을 하는데, 이는 스프링 부트가 점점 더 유연하고 다양한 설정 옵션을 제공하기 위한 진화의 일부이다. 기존 방식에서는 P6Spy를 직접 프로젝트에 적용했지만, 스프링 부트 3에서는 이 별도 프로젝트를 통해 좀 더 체계적으로 P6Spy를 설정하게 된다.
2-2. 위에서 보이는 gavlyukovskiy라는 단어는 뭘까?
- 나는 gavlyukovskiy 라는 단어가 무엇을 의미하는지 엄청 궁금했다. 분명히 누군가의 이름 같은데 이게 스프링이 직접 지원하는 무언가 폴더 같은 것인지 아니면 누군가가 본인의 이름을 넣은 채로 만들어서 배포하고 있는 것인지를 알아봤다.
gavlyukovskiy/spring-boot-data-source-decorator는 스프링에서 만들어서 배포한것이 아니라 개인 개발자인 gavlyukovskiy가 만든 오픈 소스 프로젝트다. 이 프로젝트는 스프링 부트 애플리케이션에서 P6Spy, datasource-proxy, FlexyPool 등과의 통합을 쉽게 할 수 있도록 도와준다.
스프링 부트의 설정을 통해 이 데코레이터들을 활성화하고 구성할 수 있어서, 스프링 부트 3 어플리케이션에서 SQL 쿼리 로깅 및 데이터베이스 연결 모니터링을 효과적으로 수행할 수 있게 한다.
스프링 부트의 클래스패스에 이 스타터를 추가하기만 하면, 사용자 정의 또는 자동 구성된 데이터 소스가 적절한 데이터 소스 프록시 제공자로 자동 래핑되면서, 데이터베이스 작업을 세밀하게 추적하고 관리할 수 있게 되는 것이다.
자 이제 변경된 이유를 알았으니 새로운 방법을 통해 SpringBoot3.x.x 버전의 프로젝트에 P6spy를 적용시켜 보자
3. P6Spy 수동 구성 - 의존성 추가 및 세팅하기 (starter사용 X)
3-1. p6spy decorator 수동 구성과 의존성 추가에 대한 설명
참고로 지금부터 설명할 수동으로 추가하는 방법은 build.gradle에 p6spy의 starter 의존성을 추가하지 않고 p6spy를 적용시키는 방법이다. 일반적으로 자동 구성(auto-configuration) 클래스를 직접 프로젝트에 추가하거나 커스텀 설정을 만들 때 이 방법을 사용한다. 이런 방식은 보다 세밀한 설정이나 커스터마이징이 필요한 경우에 적합하다.
참고로 gradle에는 starter의존성을 추가하지 않을 뿐이지 P6spy에 관련된 의존성은 build.gradle에 추가해 줘야 p6spy를 사용할 수 있다는 점을 꼭 명심하자
3-2. build.gradle에 P6spy 라이브러리 의존성 추가하기
수동으로 구성을 할때에는 꼭 아래의 라이브러리 2개를 추가해 줘야만 p6spy를 사용할 수 있다.
- p6spy:p6spy
- P6Spy 라이브러리 자체를 제공한다.
- com.github.gavlyukovskiy:datasource-decorator-spring-boot-autoconfigure
- 스프링 부트와 P6Spy 간의 자동 구성을 지원한다. 두 의존성 모두 build.gradle 파일에 추가하면 P6Spy를 사용할 수 있다. 이렇게 하면 P6Spy의 로깅 기능을 활용하면서도 스프링 부트의 자동 구성 기능을 유지할 수 있다.
dependencies {
// P6Spy 의존성 추가
implementation 'p6spy:p6spy:3.9.1'
implementation 'com.github.gavlyukovskiy:datasource-decorator-spring-boot-autoconfigure:1.9.0'
}
3-3. META-INF, spring 폴더 생성 및 AutoConfiguration.imports 파일 생성하기

- 위의 사진과 같이 프로젝트 내부의 resources 폴더 하위에 META-INF 폴더를 만든다.
- META-INF 폴더 하위에 spring폴더를 만든다.
- spring폴더 안에 org.springframework.boot.autoconfigure.AutoConfiguration.imports 라는 이름의 파일을 생성한다.
3-4. 파일내부 코드 작성
- org.springframework.boot.autoconfigure.AutoConfiguration.imports 파일 내부에 아래의 코드를 작성하자

참고로 아래와 같이 클래스 경로를 적은것 만으로는 p6spy가 동작하지 않는다. 이 파일은 스프링 부트의 자동 구성 시스템에 클래스를 포함시키는 역할을 하지만, 해당 클래스가 실제로 존재하려면 해당 클래스를 포함하는 라이브러리의 의존성이 프로젝트에 추가되어야 합니다. build.gradle 안에 p6spy관련 decorator 의존성을 추가해 주면 된다.
- 아래와 같이 적어주었다.
com.github.gavlyukovskiy.boot.jdbc.decorator.DataSourceDecoratorAutoConfiguration
3-5. AutoConfiguration 파일 내부에 위의 내용(com.github.gavlyukovskiy.xxxxx.xxx)을 적는 이유
org.springframework.boot.autoconfigure.AutoConfiguration.imports 파일은 스프링 부트의 자동 구성(Auto-Configuration) 메커니즘과 관련이 있다. 이 파일은 특정 클래스(여기서는 com.github.gavlyukovskiy.boot.jdbc.decorator.DataSourceDecoratorAutoConfiguration)를 스프링 부트의 자동 구성 대상으로 등록하는 역할을 한다. 즉, DataSourceDecoratorAutoConfiguration 클래스를 AutoConfiguration.imports 파일에 추가함으로써, 스프링 부트 어플리케이션 시작 시 해당 클래스가 자동으로 스프링 컨텍스트에 포함되고 구성되게 하는 것이다. 이렇게 하면, 스프링 부트는 DataSourceDecoratorAutoConfiguration을 찾아서 자동으로 설정을 적용하게 된다.
3-6. application.yml에 datasource설정하기 - 이론 설명
- DataSourceDecoratorAutoConfiguration을 사용할 때는 application.yml에서 spring.datasource.url에 직접 P6Spy 설정을 추가할 필요가 없다. 이 구성 요소는 어플리케이션의 데이터 소스를 P6Spy 객체로 자동으로 감싸거나 '래핑'하는 역할을 한다. 래핑이란, 실제 데이터베이스와의 모든 통신이 P6Spy를 통해 이루어지도록 하는 것을 의미한다. 이 방식으로, 데이터베이스와의 상호작용은 P6Spy에 의해 로깅되고 추적되며, 이 모든 과정은 사용자가 코드를 직접 수정하지 않아도 자동으로 처리되는 것이다.
즉, 위와 같이 수동으로 직접 decorator를 만들어주는 방식을 사용해서 p6spy 설정을 해주면 기존의 데이터 소스 URL을 그대로 사용할 수 있고, gavlyukovskiy의 자동 구성 기능이 나머지 작업을 처리해 준다는 것이다. 이 경우에는 단지 application.yml 또는 application.properties에서 P6Spy와 관련된 추가 설정들(로깅 형식, 로그 파일 경로 등)을 정의하기만 하면 된다.
3-7. application.yml에 datasource설정하기 - 코드 작성
- 아래와 같이 application.yml을 작성하면 된다. p6spy를 적용하기 이전이랑 코드를 비교해 보면 코드가 하나도 바뀐것이 없다. 이게 가능한 이유가 바로 p6spy를 적용할 때 자동 구성 기능이 동작하기 때문인데 이로 인해 datasource의 driver나 url에 대해서는 사용자가 아무것도 작성하거나 건드릴 필요가 없다.
spring:
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://localhost:5432/mydatabase
username: myuser
password: mypassword
3-8. 사용하기
- 이제 적용이 완료되었으니 프로젝트에서 사용하면 된다. (로깅에 대한 추가 설정은 아래에서 설명한다.)

- 위의 사진은 적용 이전이고 아래는 적용한 후의 사진이다. JPA의 쿼리에 어떤 값이 들어갔는지 보이는 것을 확인할 수 있다.

위에서 말한 기존의 데이터 소스 url을 그대로 사용할 수 있다는 말의 뜻은 datasource의 url에 p6spy와 관련된 내용이 들어가지 않아도 된다는 의미다. (이에 대한 자세한 내용은 하단의 5번 목차에 적어두었다.)
4. P6Spy 자동 구성 - 의존성 추가 및 세팅하기 (starter사용 O)
4-1. p6spy decorator 자동으로 추가하기 (gradle 의존성으로 추가하기)
위의 수동적으로 p6spy를 추가하는 방식과 다르게 build.gradle에 p6spy 전용 starter를 작성해서 p6spy를 사용하는 방법은 적용 방법이 훨씬 간단하고 편리하다. starter를 build.gradle안에 추가해주기만 하면, 스프링 부트가 나머지 필요한 구성을 자동으로 처리해 준다. 이는 기본 설정으로 P6Spy를 사용하려는 경우에 적합하다.
4-2. p6spy starter 의존성 추가하기
- 나는 Gradle을 사용 중이므로 build.gradle에 의존성을 작성했다. (참고로 SpringBoot3에서는 1.9.0 버전을 사용해야 한다.)
// p6spy
dependencies {
implementation 'com.github.gavlyukovskiy:p6spy-spring-boot-starter:1.9.0'
}- 만약 Maven을 사용 중이라면 pom.xml에 아래와 같이 작성하면 된다.
<dependency>
<groupId>com.github.gavlyukovskiy</groupId>
<artifactId>p6spy-spring-boot-starter</artifactId>
<version>${version}</version>
</dependency>
4-3. application.yml에 datasource 설정
- 이렇게 gradle을 활용하여 p6spy-starter를 적용하는 방법 또한 application.yml의 spring.datasource.url에 p6spy에 관련된 코드를 명시적으로 추가할 필요가 없다. 이 starter는 내부적으로 필요한 P6Spy 구성을 자동으로 처리해 준다. spring.datasource.url에는 아래와 같이 기존 데이터베이스 URL을 그대로 사용하면 된다. (이것도 하단의 5번 목차에 자세한 내용을 적어뒀다.)
spring:
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://localhost:5432/mydatabase
username: myuser
password: mypassword
4-4. 사용하기
- 이제 p6spy의 세팅이 완료되었으니 사용하면 된다. (로깅에 대한 추가설정은 아래의 글을 참고하자)

- 위의 사진은 적용 이전이고 아래는 적용한 후의 사진이다. JPA의 쿼리에 어떤 값이 들어갔는지 보이는 것을 확인할 수 있다.
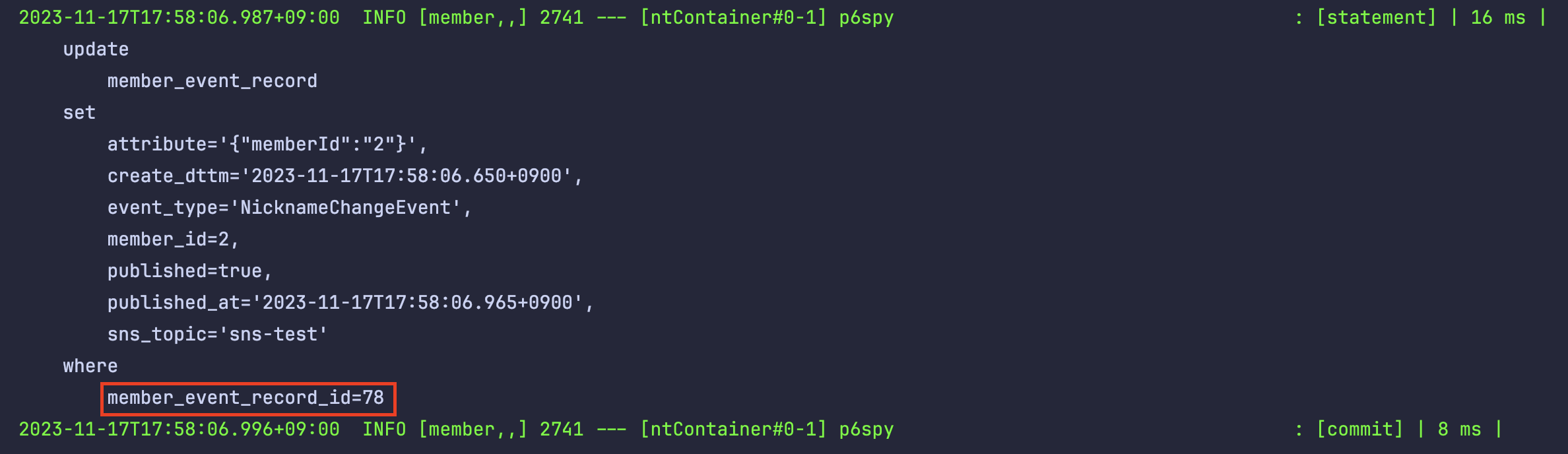
5. p6spy의 자동 구성 기능의 활성화에 따른 datasource의 url 작성방식 비교
5-1. 자동 구성이 비활성화 상태일 때 application.yml의 datasource 작성방법
- 만약 p6spy의 자동 구성 기능이 설정되지 않았을 때에는 아래처럼 url안에 jdbc:p6spy를 적어줘야 했으며 driver-class-name도 설정해줬어야 했다.
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
url: jdbc:p6spy:postgresql://localhost:5432/mydatabase
username: myuser
password: mypassword
5-2. 자동 구성이 활성화 상태일 때 application.yml의 datasource 작성방법
- 우리는 자동구성을 설정했으니 아래와 같이 p6spy관련 내용은 제외하고 적어줘도 되는 것이다.(편해지고 보기 좋아짐)
spring:
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://localhost:5432/mydatabase
username: myuser
password: mypassword
6. P6spy의 2가지 로깅 설정방법 (application.yml, spy.properties)
6-1. 둘 중에 어떤 것을 선택할 것인가?
1. application.yml 사용
이 방법은 스프링 부트 프로젝트에서 스프링 환경 설정 파일을 통해 P6Spy 설정을 하는 경우에 적합하다. gavlyukovskiy/spring-boot-data-source-decorator 스타터를 사용하는 경우, spring.datasource.p6spy 설정을 통해 로깅을 구성할 수 있다.
2. spy.properties 사용
이 파일은 스프링 부트와 관계없이 P6Spy 자체적으로 제공하는 설정 파일이다. 스프링 환경 설정 파일과 독립적으로 작동하며, 스프링 부트를 사용하지 않는 일반 자바 프로젝트에서 P6Spy를 설정할 때 유용하다.
3. 결론
결론적으로 두 방법은 서로 중복되지 않으며, 상황에 따라 적절한 방법을 선택하면 된다. 다만 일반적으로 스프링 부트 프로젝트에서는 application.yml을 사용하는 것이 더 편리하고 일관된 방법이 될 것이다.
6-2.application.yml을 사용한 p6spy 로깅 설정
지금부터의 내용은 p6spy의 공식 깃허브 설명 내용을 기준으로 설명한다.
- p6spy의 공식 페이지(깃허브)에 들어가 보면 아래와 같이 application.yml에 로깅관련 설정을 해주라고 적혀있다. 적혀있는 설정방법과 조금 다르게 적어야 할 점이 있는데 나는 SpringBoot를 통한 설정이므로 아래 예시를 보면 맨앞에 decorator.xxx.xx 이런식으로 적혀있는데 나는 맨앞의 내용이 decorator를 제거하고 이부분을 spring으로 변경시켜서 적어주면 된다.
GPT는 나에게 아래와 같이 알려줬다.
application.yml에서 설정을 정의할 때는 decorator.datasource 대신 spring.datasource 아래에 설정을 추가해야 한다. gavlyukovskiy/spring-boot-data-source-decorator의 설정들은 spring.datasource 하위에서 관리되는 것이 일반적이다.
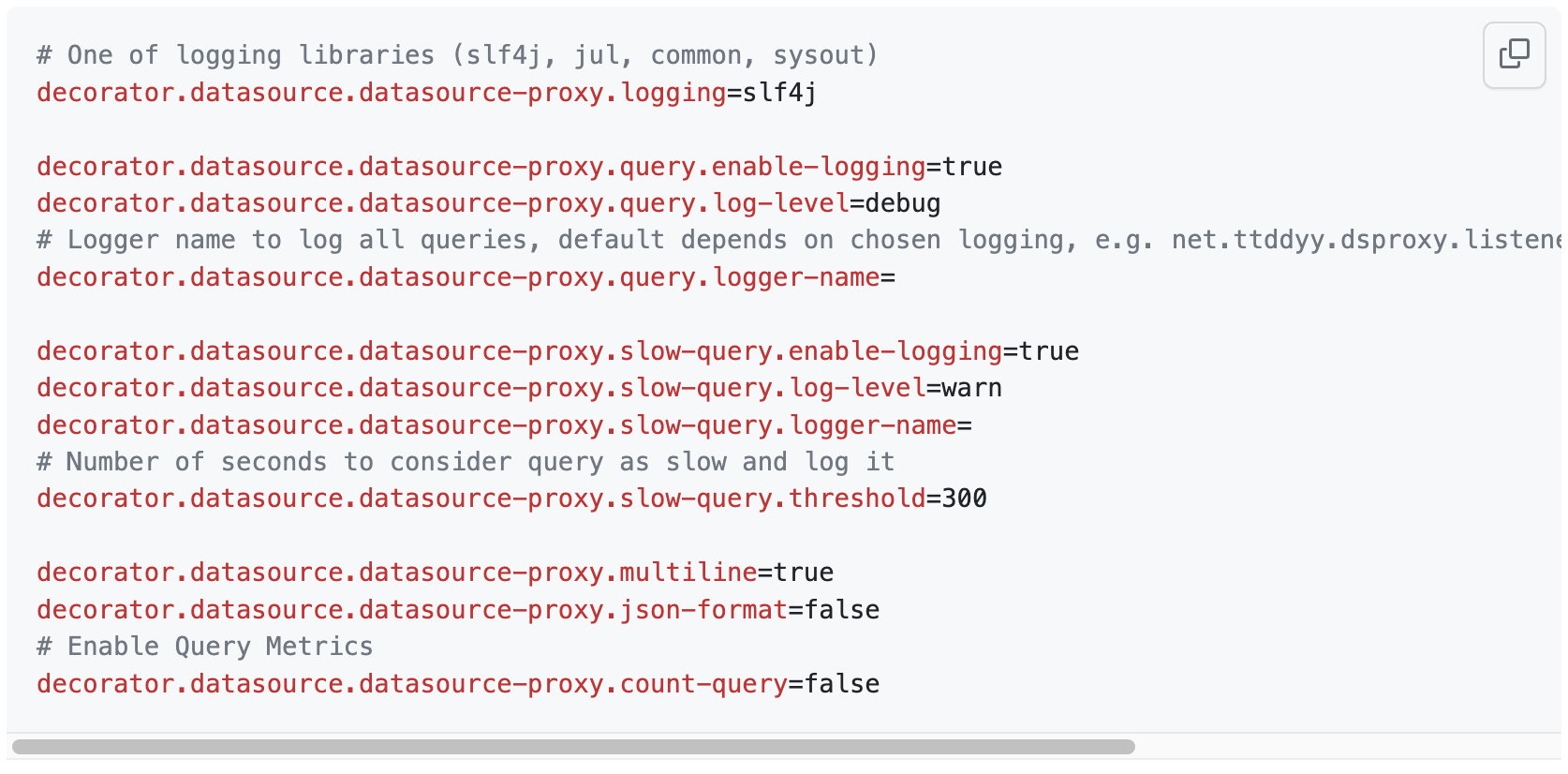
6-2-1. p6spy 로깅 필수 설정값 작성 (application.yml)
spring:
datasource:
p6spy:
# JDBC 이벤트 로깅을 위한 P6LogFactory 등록
enable-logging: true
# com.p6spy.engine.spy.appender.MultiLineFormat 사용 (SingleLineFormat 대신)
multiline: true
# 기본 리스너들을 위한 로깅 사용 [slf4j, sysout, file, custom]
logging: slf4j
# 실제 값으로 '?'를 대체한 효과적인 SQL 문자열을 추적 시스템에 보고
# 참고: 이 설정은 로깅 메시지에 영향을 주지 않음
tracing:
include-parameter-values: true
6-2-2. p6spy 로깅 커스텀 설정값 작성: 이것은 선택사항이다. (application.yml)
spring:
datasource:
p6spy:
# 파일 로깅 사용 시 로그 파일 지정: 로그 파일 사용 (logging=file일 때만)
log-file: spy.log
# 커스텀 로거 클래스 지정: 사용할 클래스 파일 (logging=custom일 때만). 클래스는 com.p6spy.engine.spy.appender.FormattedLogger를 구현해야 함
custom-appender-class: my.custom.LoggerClass
# 커스텀 로그 포맷 지정: 지정하면 com.p6spy.engine.spy.appender.CustomLineFormat이 이 로그 포맷으로 사용됨
log-format:
# 로그 메시지 필터링을 위한 정규 표현식 패턴 사용: 지정되면 일치하는 메시지만 로깅됨
log-filter:
pattern:
6-3. spy.properties 파일을 사용한 로깅 상세설명
- spy.properties 파일은 P6Spy 라이브러리의 구성을 위한 독립적인 설정 파일로, 스프링 부트 환경과는 별개로 작동한다. 이 파일을 사용하면, 스프링 부트를 사용하지 않는 표준 자바 프로젝트에서도 P6Spy의 로깅 기능을 세밀하게 조정할 수 있다. spy.properties 파일을 프로젝트의 resources 디렉토리에 추가하여, 로깅 형식, 로그 파일의 경로와 같은 P6Spy 설정을 커스터마이즈 할 수 있다. 이 방법은 스프링 환경 설정과는 독립적으로 P6Spy를 세부적으로 구성하고자 할 때 특히 유용하다.
6-3-1. spy.properties 작성
- 이 설정은 P6Spy가 생성하는 로그를 SLF4J를 통해 처리하도록 설정한다.
# SLF4J를 사용한 로깅을 위한 설정
appender=com.p6spy.engine.spy.appender.Slf4JLogger
# 로그 파일의 위치와 이름 설정 (Slf4JLogger를 사용하는 경우, 로그 설정 파일에서 관리됨)
# logfile=spy.log
# 로그 형식 설정
logMessageFormat=com.p6spy.engine.spy.appender.CustomLineFormat
# 커스텀 로그 형식
customLogMessageFormat=%(currentTime)|%(executionTime)|%(category)|%(sqlSingleLine)
# 로깅 필터링을 위한 정규 표현식
filter=false
# SQL 포맷팅을 활성화
sqlformat=true
이번에 P6spy에 대한 내용은 적용을 해봤던 것을 간단하게 정리하려고 했던 것이 이렇게 길어져버렸다. 이번에 SpringBoot3을 쓰면서 기존과는 적용 방법이 조금 달라진(큰 차이가 없고 거의 비슷하긴 하다.) p6spy라는 기술에 대해서 탐구해 보면서 확실히 이런 중요한 기술들은 어떻게 적용하는 것이고 내부적으로 어떤 동작을 하는지 잘 모르고 쓰는 것보다는 내가 이것을 어떻게 적용했으며 왜 적용방법이 변경되었는지를 아는 것이 중요하다는 것을 느꼈다.
내용 출처
Integrating P6Spy — p6spy 3.9.2-SNAPSHOT documentation
A very typical use case for P6Spy is to enabled SQL logging to troubleshoot various database related issues during development. Assuming that making code changes is acceptable, then the following instructions can be used. If making code changes is not a vi
p6spy.readthedocs.io
https://www.baeldung.com/java-p6spy-intercept-sql-logging
Intercept SQL Logging with P6Spy | Baeldung
Explore multiple advantages of relying on an external third-party library such as P6Spy to log database queries.
www.baeldung.com
https://github.com/gavlyukovskiy/spring-boot-data-source-decorator
GitHub - gavlyukovskiy/spring-boot-data-source-decorator: Spring Boot integration with p6spy, datasource-proxy, flexy-pool and s
Spring Boot integration with p6spy, datasource-proxy, flexy-pool and spring-cloud-sleuth - GitHub - gavlyukovskiy/spring-boot-data-source-decorator: Spring Boot integration with p6spy, datasource-p...
github.com
이 포스트는 Team chillwave에서 사이드 프로젝트를 하던 중 적용했던 부분을 다시 공부하면서 기록한 것입니다.
시간이 난다면 팀원 평양냉면7 님의 블로그도 들려주세요! 좋은 지식들이 많이 있습니다!
하다보니 재미있는 개발
하다 보니 재미있는 개발에 빠져있는 중입니다. 문의사항: ysoil8811@gmail.com
yijoon009.tistory.com
'Spring > JPA' 카테고리의 다른 글
| [Spring] Redis에서 RDB로 조회수 동기화하기 (25) | 2024.02.10 |
|---|---|
| JPA N+1 문제가 발생하는 상황과 해결방법 (5) | 2023.12.28 |
| [Spring] Data JPA의 구조를 알아보자 (1) | 2023.10.24 |
| Spring JPA - 데이터 영속화란? (0) | 2023.08.13 |
| Spring JPA - 엔티티를 DTO로 바꿔서 사용하는 이유 (0) | 2023.08.13 |